Codeql使用学习
安装
https://github.com/github/codeql-cli-binaries/releases去这里下载codeql执行程序,然后设置环境变量,指定到codeql文件夹
这样就设置成功了
下载SDK:https://github.com/github/codeql,下载后解压重命名为ql文件夹,与前面codeql同目录
vscode配合codeql
下载插件后,配置codeql文件地址
接下来创建数据库来测试一下
这里选择https://github.com/l4yn3/micro_service_seclab/这个项目来测试
接下来创建数据库,命令一般是
1
|
codeql database create <数据库名> --language=<语言标识符> --source-root=<源码路径>
|
如果是maven项目的话,还需要加上command参数
1
|
--command="mvn clean install"
|
这里我们直接在下载的这个靶场的目录下创建,无需指定源码路径了
1
|
codeql database create codeqltest --language=java
|
执行成功的话会出现codeqltest文件夹,这里java版本要是jdk1.8的
现在打开vscode
添加数据库,这里打开要在codeql同目录下打开,然后上面语言选择java
然后可以在下面的queries里面添加我们想要的ql查询语句进行查询,我们回到sdk的目录,在java/ql/examples下面创建一个demo.ql
语法
codeql语法有点像sql,CodeQL 引擎的作用就是帮我们把源码转换为 CodeQL 能识别的数据库,所以我们能做的就是编写 QL 规则,再通过其引擎来运行我们的规则,这样就可以达到一个自动审计的功能
基本语法
1
2
3
4
5
|
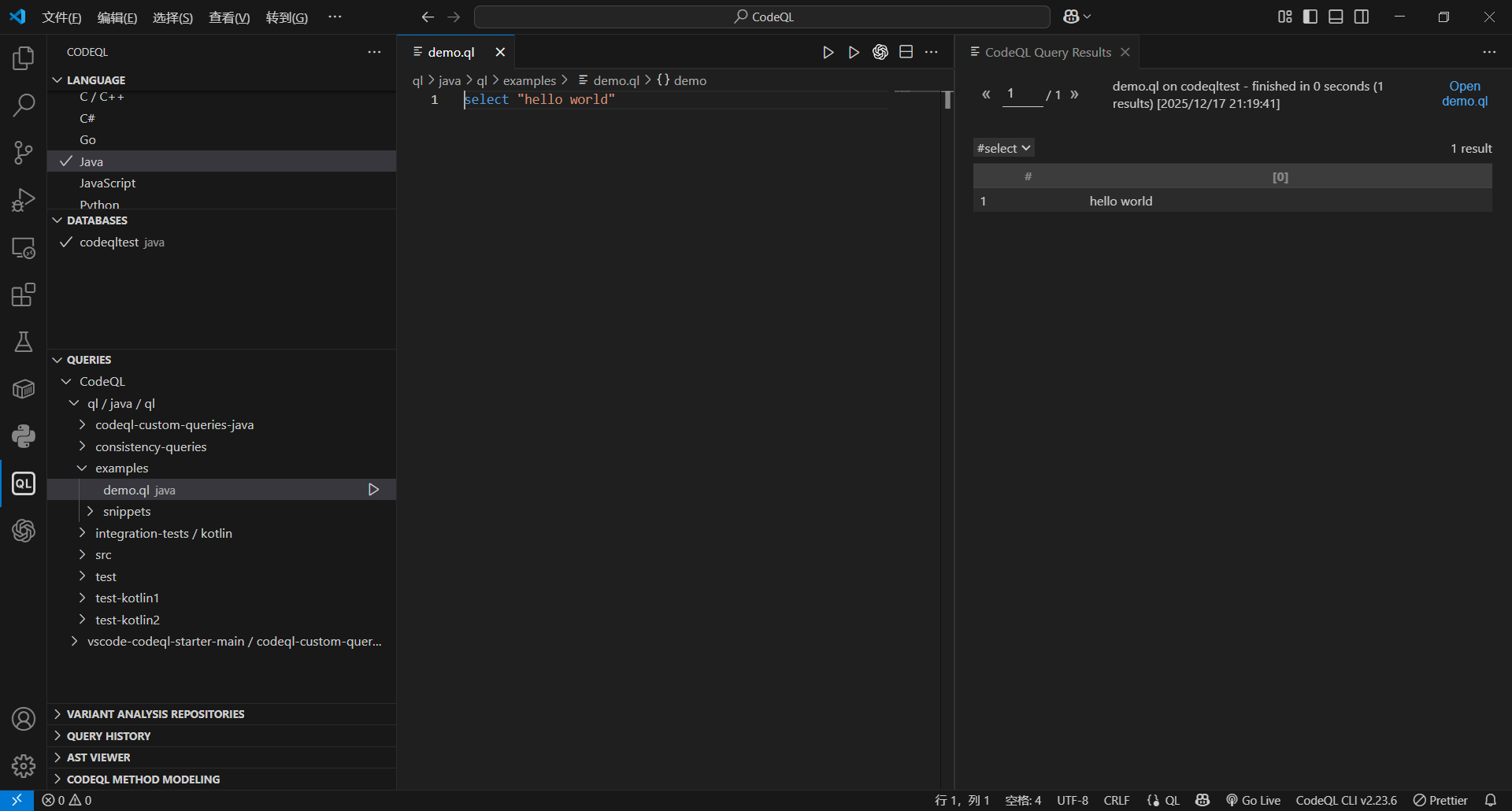
import java
from int i
where i = 1
select i
|
from int i,表示我们定义一个变量i,它的类型是int,表示我们获取所有的int类型的数据
where i = 1, 表示当i等于1的时候,符合条件
select i,表示输出i
所以codeql的语法结构为
1
2
3
|
from [datatype] var
where condition(var = something)
select var
|
类库
我们经常会用到的ql类库大体如下:
| 名称 |
解释 |
| Method |
方法类,Method method表示获取当前项目中所有的方法 |
| MethodAccess |
方法调用类,MethodAccess call表示获取当前项目当中的所有方法调用 |
| Parameter |
参数类,Parameter表示获取当前项目当中所有的参数 |
在现在的版本中MethodAccess 被重名成 MethodCall 了
我们现在可以来查询一下我们这个项目的所有方法
1
2
3
4
|
import java
from Method kkk
select kkk
|
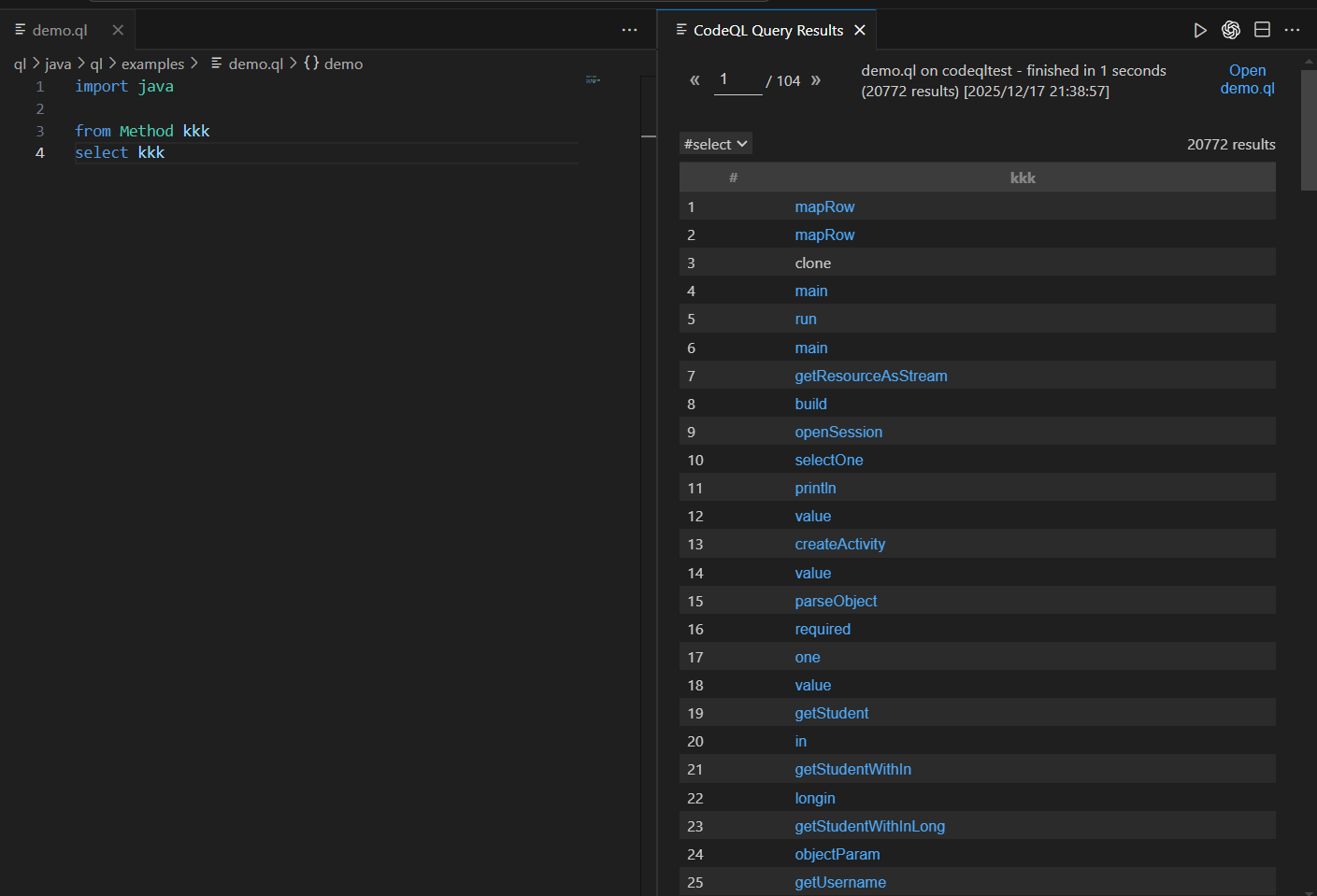
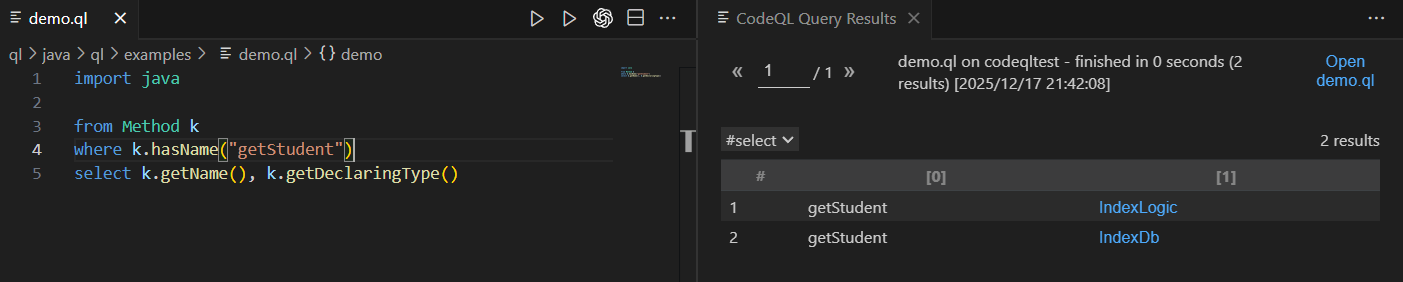
可以查询到超级多方法,我们可以过滤出名字为 getStudent 的方法名称
1
2
3
4
5
|
import java
from Method k
where k.hasName("getStudent")
select k.getName(), k.getDeclaringType()
|
1
2
3
|
k.hashName() 判断名字是否匹配
k.getName() 获取的是当前方法的名称
k.getDeclaringType() 获取的是当前方法所属class的名称
|
谓词
如果限制条件比较多,where 语句就会很冗长。CodeQL提供一种机制可以帮助我们把很长的查询语句封装成函数,而这个函数,就叫谓词。
比如上面的案例,我们可以写成如下,获得的结果跟上面是一样的:
1
2
3
4
5
6
7
8
9
|
import java
predicate isStudent(Method k) {
k.getName()="getStudent"
}
from Method k
where isStudent(k)
select k.getName(), k.getDeclaringType()
|
source和sink
source、sink以及sanitizer这个学过静态分析的不可能不知道,这里不多说了
只有当source和sink同时存在,并且从source到sink的链路是通的,才表示当前漏洞是存在的。
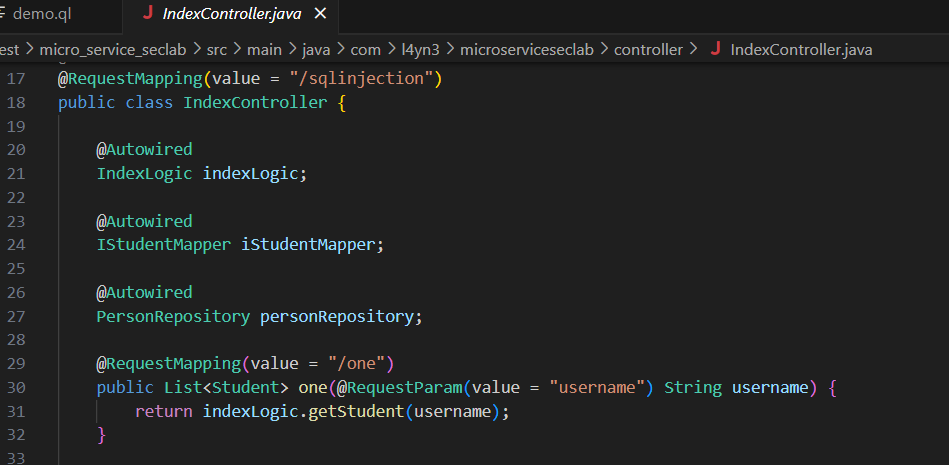
显然这里是一个source
设置source
在CodeQL中我们通过以下方法来设置Source
1
|
override predicate isSource(DataFlow::Node src) {}
|
由于上面的source是http请求参数
我们设置的source就为
1
|
override predicate isSource(DataFlow::Node src) { src instanceof RemoteFlowSource }
|
RemoteFlowSource 是 CodeQL 标准库中预定义的 “远程数据源” 类,比如HTTP 请求参数,用户输入以及其他外部输入等
这是SDK自带的规则,里面包含了大多常用的Source入口。我们使用的SpringBoot也包含在其中,可以直接使用。
注: instanceof 语法是CodeQL提供的语法,这里就是检查获得的 src 是否为 RemoteFlowSource
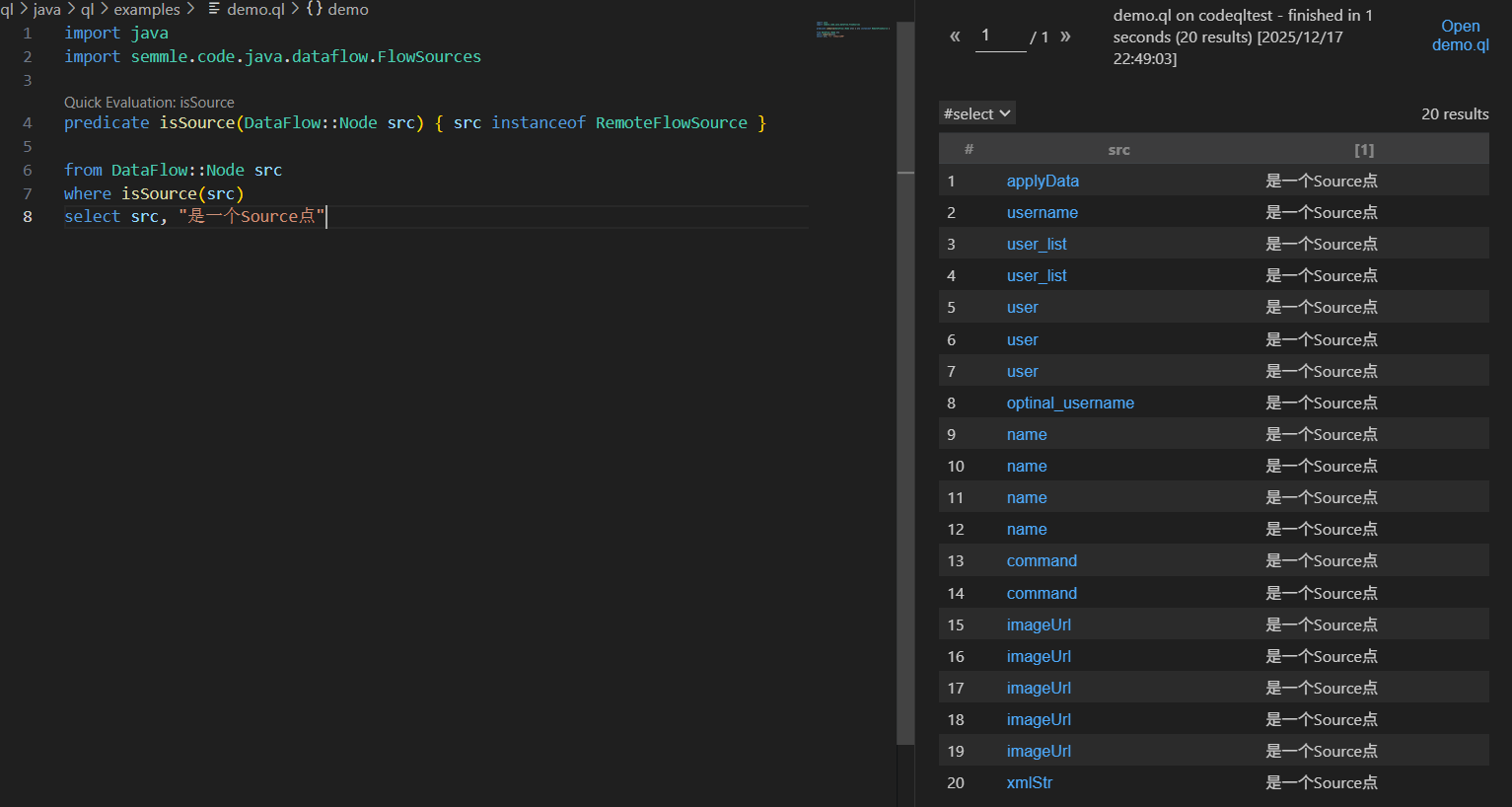
这里测试输出所有可能的source点,其实就是有http请求参数
1
2
3
4
5
6
7
8
|
import java
import semmle.code.java.dataflow.FlowSources
predicate isSource(DataFlow::Node src) { src instanceof RemoteFlowSource }
from DataFlow::Node src
where isSource(src)
select src, "是一个Source点"
|
设置sink
在CodeQL中我们通过以下方法来设置Sink
1
|
override predicate isSink(DataFlow::Node sink) {}
|
在实际中,我们最后都是触发到某个恶意方法,如 getter,setter,所以 sink 应该是个方法,假设我们这里的sink 点是个query方法(Method)的调用(MethodCall),所以我们设置Sink为:
1
2
3
4
5
6
7
8
|
override predicate isSink(DataFlow::Node sink) {
exists(Method method, MethodCall call |
method.hasName("query")
and
call.getMethod() = method and
sink.asExpr() = call.getArgument(0)
)
}
|
这里我们使用了exists子查询,这个是CodeQL谓词语法里非常常见的语法结构,它根据内部的子查询返回true or false,来决定筛选出哪些数据。
sink.asExpr() = call.getArgument(0):将 sink 节点转换为表达式,并检查它是否等于 call 的第一个参数
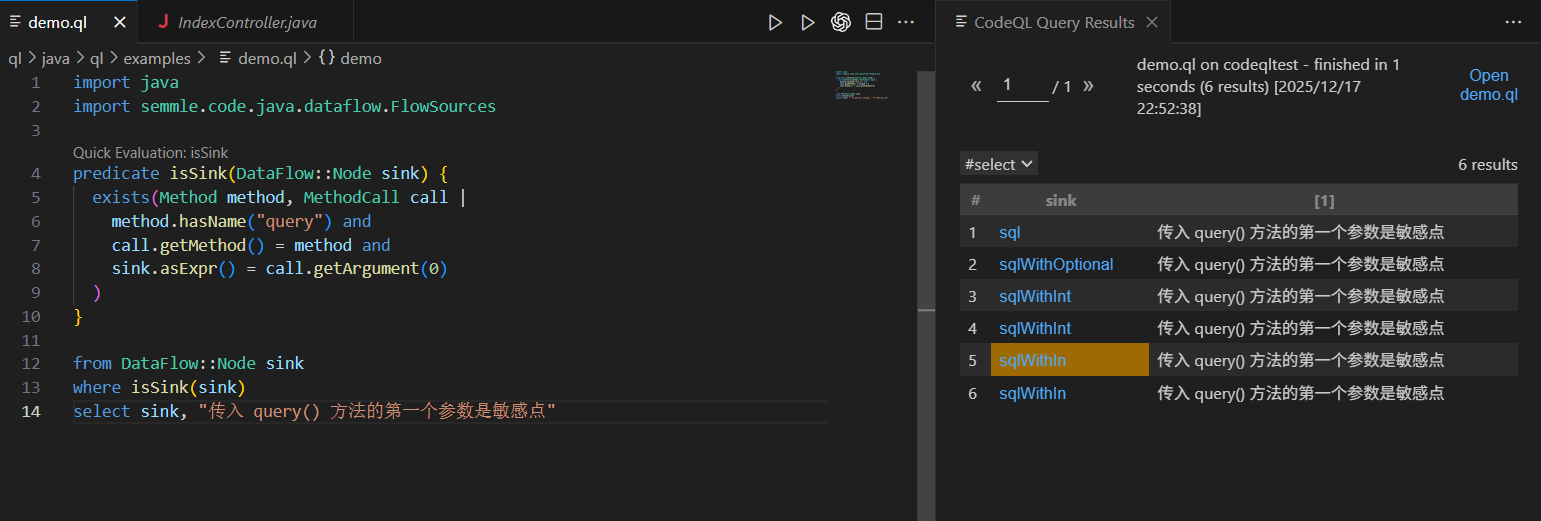
故上面sink语句的作用是查找一个query()方法的调用点,并把它的第一个参数设置为sink
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java
import semmle.code.java.dataflow.FlowSources
predicate isSink(DataFlow::Node sink) {
exists(Method method, MethodCall call |
method.hasName("query") and
call.getMethod() = method and
sink.asExpr() = call.getArgument(0)
)
}
from DataFlow::Node sink
where isSink(sink)
select sink, "传入 query() 方法的第一个参数是敏感点"
|
点进第一个实际上就确实是sql注入漏洞点
1
|
jdbcTemplate.query(sql, ROW_MAPPER);
|
flow数据流
确定了上面的source和sink,现在要找中间的链子了
这个连通工作就是CodeQL引擎本身来完成的。我们通过使用config.hasFlowPath(source, sink)方法来判断是否连通。
1
2
3
|
from VulConfig config, DataFlow::PathNode source, DataFlow::PathNode sink
where config.hasFlowPath(source, sink)
select source.getNode(), source, sink, "source"
|
我们传递给config.hasFlowPath(source, sink)我们定义好的source和sink,系统就会自动帮我们判断是否存在漏洞了。
source.getNode():获取源节点的底层语法树节点(AST Node),显示漏洞源头在代码中的具体位置
实操
现在来试着探测sql注入的可行性,这里l3yx师傅在freebuff上那种写法在新版已经被弃用了,在新版 CodeQL中,数据流分析(DataFlow)和污点跟踪(TaintTracking)的 API 发生了重大变化。旧的 TaintTracking::Configuration 类已被弃用,取而代之的是模块化(Modular) 的写法。
然后我让gemini生成一个新版可用的ql代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
/**
* @id java/examples/vuldemo
* @name Sql-Injection
* @description Sql-Injection
* @kind path-problem
* @problem.severity warning
*/
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.TaintTracking
import semmle.code.java.dataflow.FlowSources
// 1. 定义配置模块,实现 DataFlow::ConfigSig 签名
module VulConfig implements DataFlow::ConfigSig {
// 定义 Source (污染源)
predicate isSource(DataFlow::Node source) {
source instanceof RemoteFlowSource
}
// 定义 Sink (汇聚点)
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
// 查找方法名为 "query" 的调用
call.getMethod().hasName("query") and
// sink 是该调用的第一个参数
sink.asExpr() = call.getArgument(0)
)
}
}
// 2. 使用 TaintTracking::Global 模板生成具体的分析模块
module VulFlow = TaintTracking::Global<VulConfig>;
// 3. 从生成的模块中导入 PathGraph (解决 import DataFlow::PathGraph 报错的问题)
import VulFlow::PathGraph
from VulFlow::PathNode source, VulFlow::PathNode sink
where VulFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "Detected SQL Injection from $@", source.getNode(), "source"
|
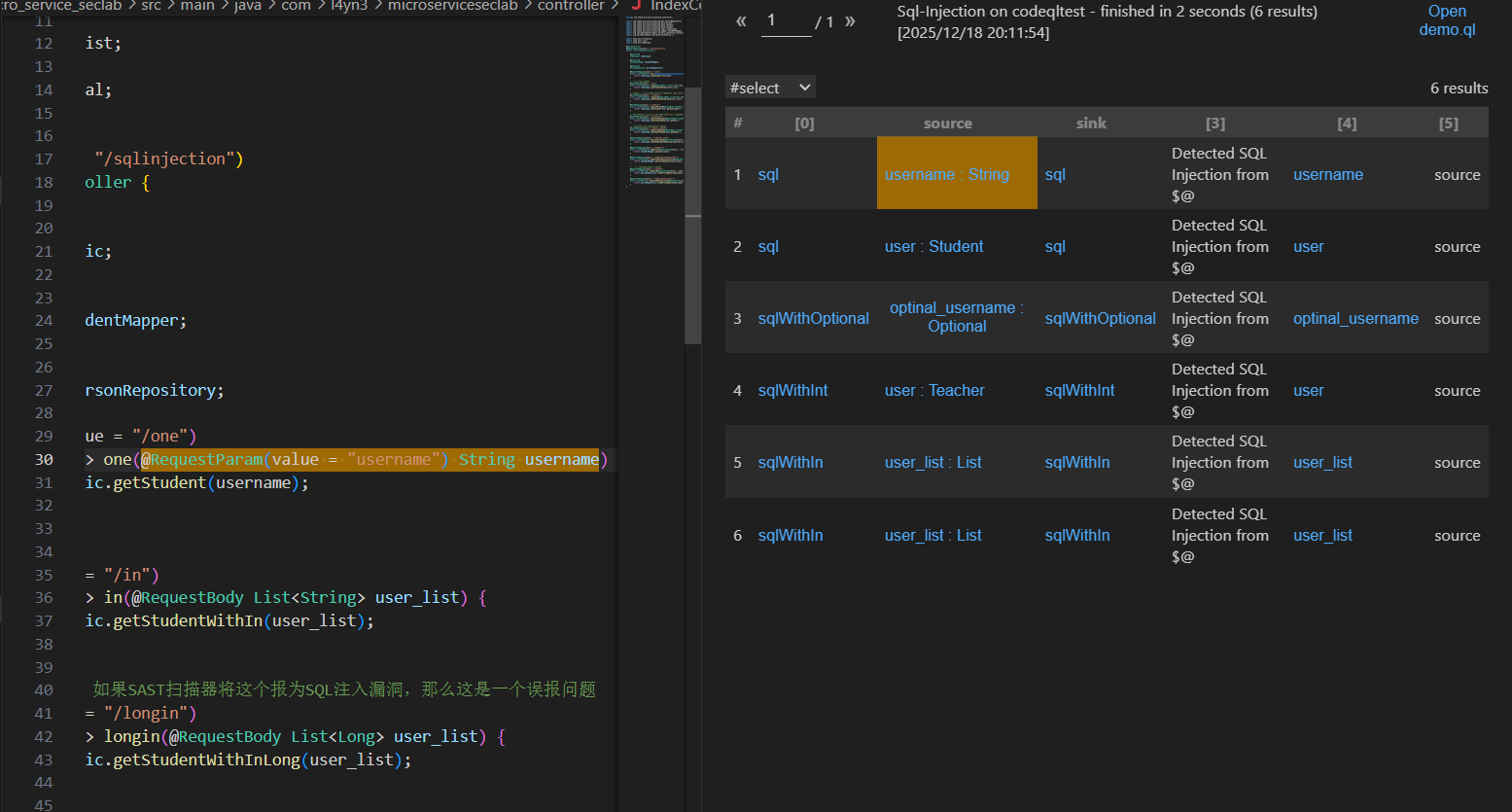
然后左上角点成alert就能看到完整的gadget
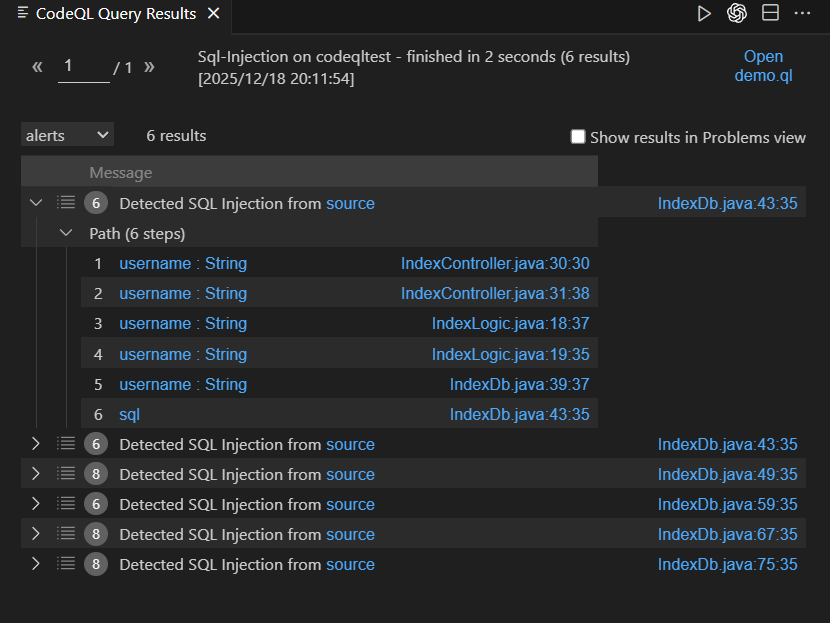
这里解释一下后面的代码
1
2
3
4
5
6
|
// 3. 从生成的模块中导入 PathGraph (解决 import DataFlow::PathGraph 报错的问题)
import VulFlow::PathGraph
from VulFlow::PathNode source, VulFlow::PathNode sink
where VulFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "Detected SQL Injection from $@", source.getNode(), "source"
|
- DataFlow::Node:代表代码中的一个点(比如一个变量、一个参数)。它关注的是代码位置。
- PathNode:代表数据流路径图中的一个节点。它包裹了 DataFlow::Node,但它专为路径追踪设计。
- VulFlow::flowPath(source, sink)判断两个 PathNode(起点和终点)之间是否存在一条完整的、可达的污点传播路径。相比与flow函数,flow函数只告诉你 node1 能流到 node2,是个布尔值(True/False),不包含中间经过了谁。
- 最后PathGraph用来在结果中生成edges这个谓词,PathGraph 模块自动把 VulFlow 计算出的所有数据流关系转换成图的边(edges)。必须引用这个,不然最后看不到gadget
在CodeQL中存在两种数据流:
- 本地数据流:本地数据流是指单个方法或可调用函数内的数据流。本地数据流通常比全局数据流更简单、更快速、更精确,并且足以应对许多查询。
- 全局数据流:全局数据流跟踪整个程序的数据流,因此比局部数据流更强大。然而,全局数据流的精确度低于局部数据流,并且分析通常需要更多的时间和内存。
这里我们当然先学习全局数据流,本地数据流相对而言效果不是太好,我们需要通过实现签名DataFlow::ConfigSig和应用模块来使用全局数据流库DataFlow::Global<ConfigSig>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java
import semmle.code.java.dataflow.DataFlow
module MyFlowConfiguration implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) {
...
}
predicate isSink(DataFlow::Node sink) {
...
}
}
module MyFlow = DataFlow::Global<MyFlowConfiguration>;
|
isSource– 定义数据流出的位置。isSink– 定义数据流向何处。isBarrier– 可选,定义数据流被阻止的位置。isAdditionalFlowStep– 可选,添加额外的流程步骤。
如果想使用污点追踪,需要使用TaintTracking:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java
import semmle.code.java.dataflow.TaintTracking
module MyFlowConfiguration implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) {
...
}
predicate isSink(DataFlow::Node sink) {
...
}
}
module MyFlow = TaintTracking::Global<MyFlowConfiguration>;
|
最后使用使用谓词执行数据流分析:flow(DataFlow::Node source, DataFlow::Node sink)
1
2
3
|
from DataFlow::Node source, DataFlow::Node sink
where MyFlow::flow(source, sink)
select source, "Data flow to $@.", sink, sink.toString()
|
总结上面的,得到完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module SourceToSinkConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof RemoteFlowSource }
predicate isSink(DataFlow::Node sink) {
exists(Method method, MethodCall call |
method.hasName("query") and
call.getMethod() = method and
sink.asExpr() = call.getArgument(0)
)
}
}
module SourceToSink = TaintTracking::Global<SourceToSinkConfig>;
from DataFlow::Node source, DataFlow::Node sink
where SourceToSink::flow(source, sink)
select source, "flow to", sink
|
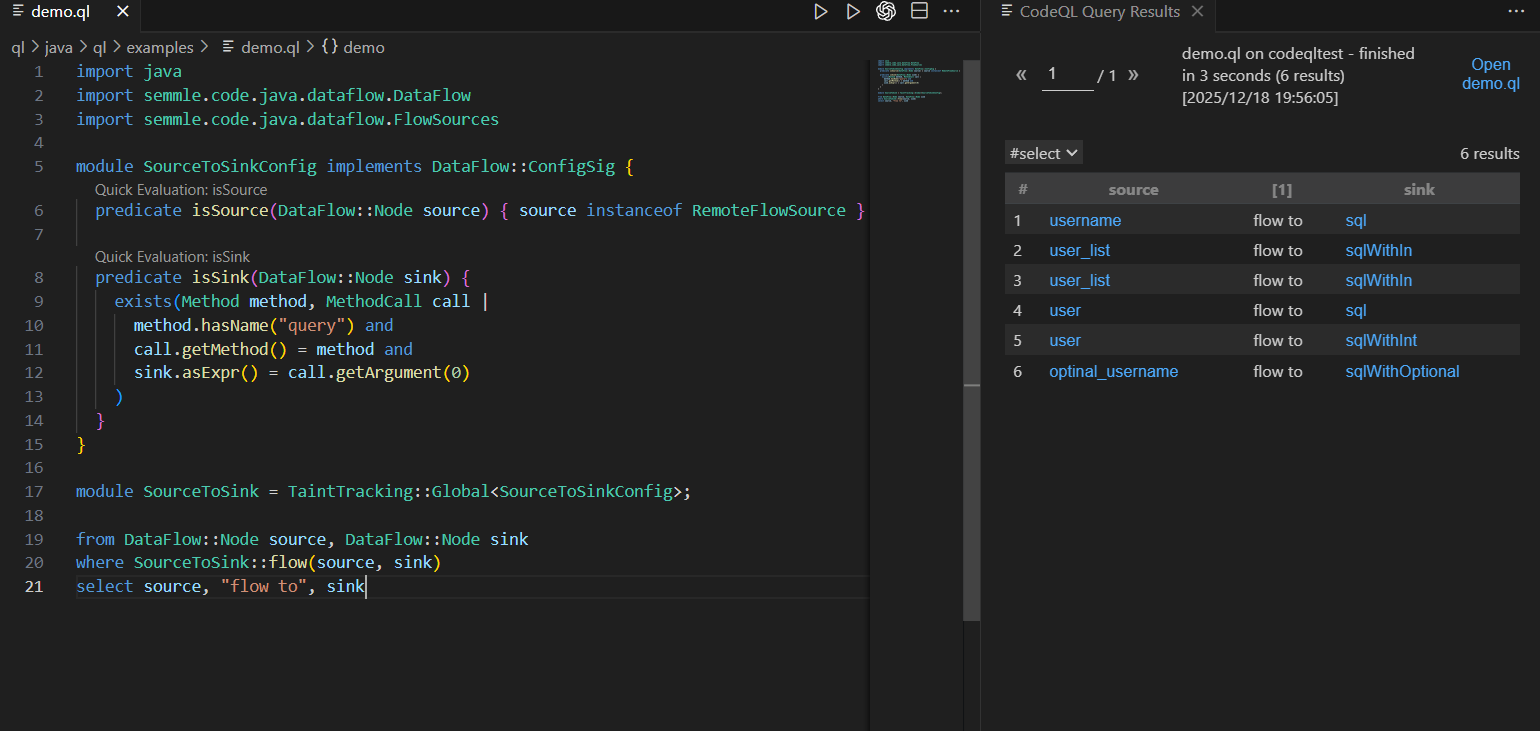
点前面两个确实是对的,但是第三个出现了误报了
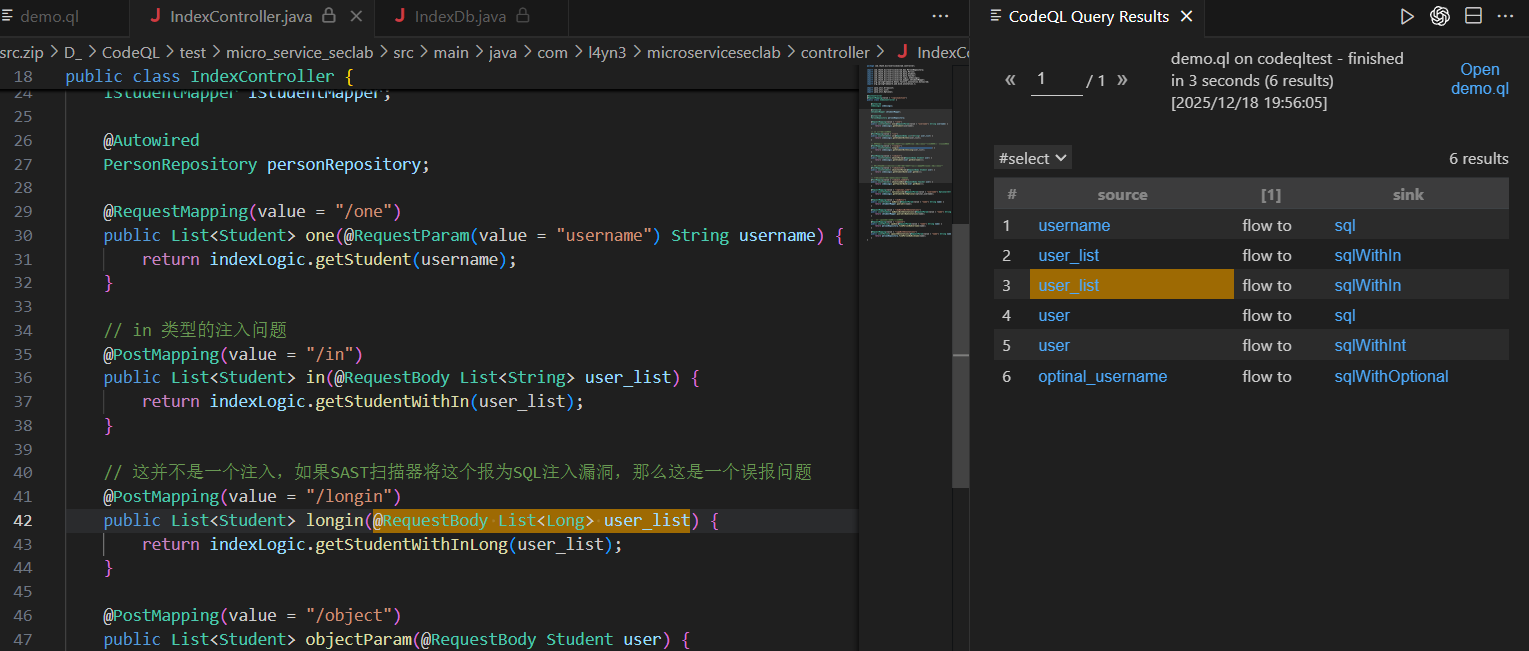
现在来解决上面的误报问题,因为我们最开始写的那个也会误报这个List<Long>的参数,因为我们的查询没有设置参数类型,这里用isSanitizer来实现排除误报,要是判断到传入类型是基础类型、数字类型、泛型数字类型时,就切断数据流
1
2
3
4
5
6
7
8
9
10
11
|
predicate isBarrier(DataFlow::Node sanitizer) {
sanitizer.getType() instanceof PrimitiveType
or
sanitizer.getType() instanceof BoxedType
or
sanitizer.getType() instanceof NumberType
or
exists(ParameterizedType pt |
sanitizer.getType() = pt and pt.getTypeArgument(0) instanceof NumberType // 这里的 ParameterizedType 代表所有泛型,判断泛型当中的传参是否为 Number 型
)
}
|
直接添加上去,查询发现确实去掉了前下的误报的链子
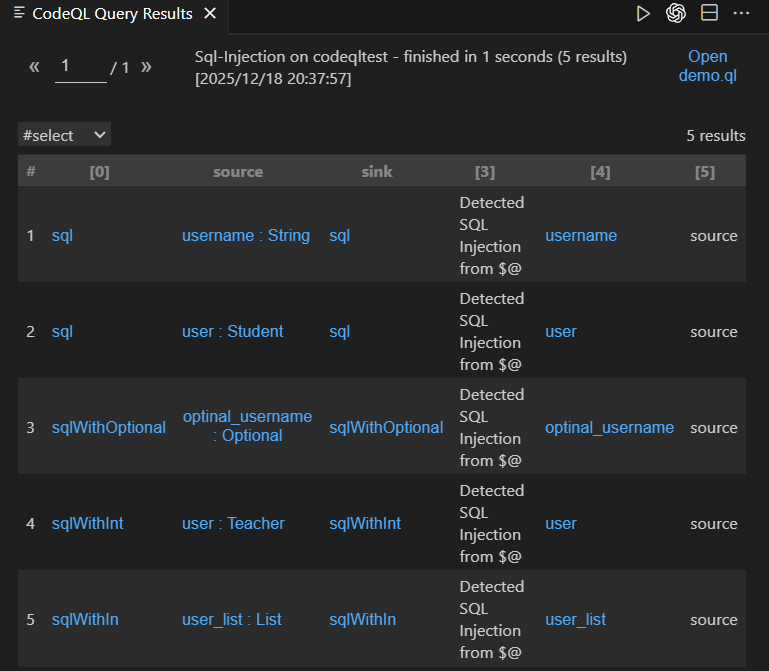
小技巧
递归
CodeQL里面的递归调用语法是:在谓词方法的后面跟*或者+,来表示调用0次以上和1次以上(和正则类似),0次会打印自己。
例如:
1
2
3
4
5
|
import java
from Class classes
where classes.getName().toString() = "innerTwo"
select classes.getEnclosingType().getEnclosingType().getEnclosingType() // getEnclosingtype获取作用域
|
我们想要调用classes的上层作用域,一直写这玩意很麻烦,我们在调用方法后面加*(从自身开始调用)或者+(从上一级开始调用),来解决此问题。
1
2
3
|
from Class classes
where classes.getName().toString() = "innerTwo"
select classes.getEnclosingType+() // 获取作用域
|
+ 是从上一级开始调用
* 是从自身开始调用
强制类型转换
在 CodeQL 中可以用 getType() 来对返回结果做强制类型转换
查询下当前数据库中所有的参数及其类型
1
2
3
4
|
import java
from Parameter param
select param, param.getType()
|
后面加上指定的参数类型就会查询对应剩下的类型
1
2
3
4
|
import java
from Parameter param
select param, param.getType().(IntegeralType)
|
