2025L3HCTFwp
赛博侦探
纯纯misc🙃
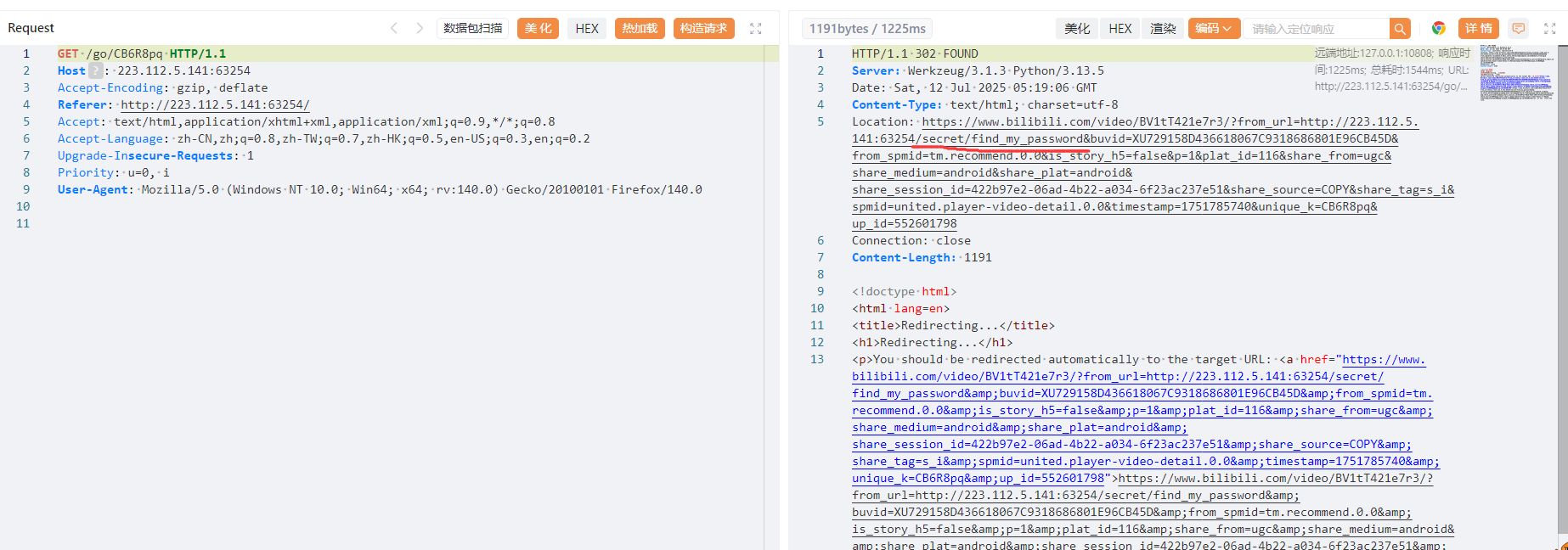
视频抓包发现路由secret/find_my_password
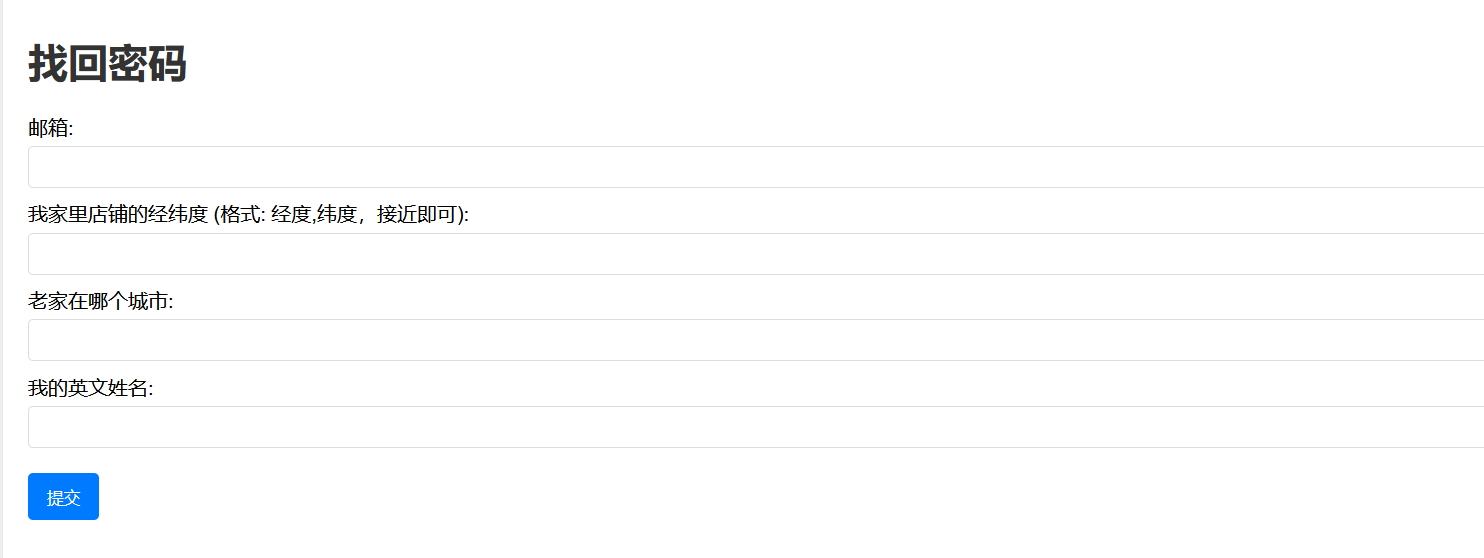
开始社工
扫描航班条形码得到

直接问ai得到航班信息
1
2
3
4
5
|
中国东方航空 MU5399
路线:武汉 → 福州
乘客:LELAND
日期:第185天(约7月4日)
座位:45L
|
乘客名LELAND,然后老家在福州
下面还有个docx,随波逐流

改后缀为zip,解压在core.xml里面找到邮箱

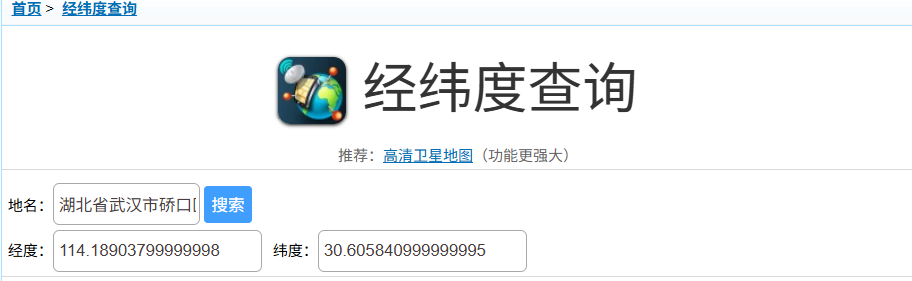
接着查找经纬度,先查看羽毛球馆位置
爆破
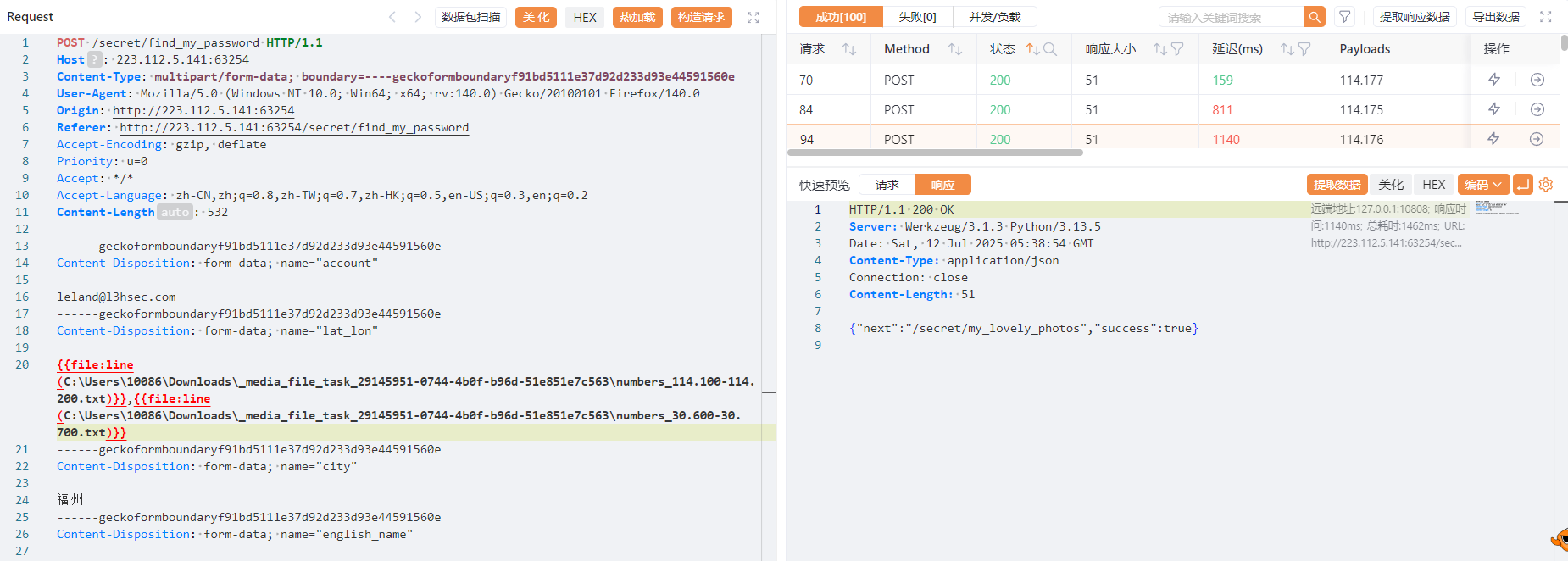
查看新路由/secret/my_lovely_photos
查看网页源码发现name参数,尝试目录穿越得到flag

量子双生影
刚开始解压是只有一张图的,扫描得到
flag is not here,but I can give you the key:“quantum”
后面看看题目,感觉是有两张图
7-zip解压得到两张图片,都是被ai改过的二维码
想到双图按位异或,但是stegsolve和随波逐流都整不出来
ai写脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
import cv2
import numpy as np
def webp_xor(image1_path, image2_path, output_path):
"""
对两张WebP图片进行按位异或(XOR)操作并保存结果
参数:
image1_path: 第一张WebP图片路径
image2_path: 第二张WebP图片路径
output_path: 输出图片路径
"""
# 读取两张WebP图片
img1 = cv2.imread(image1_path, cv2.IMREAD_UNCHANGED)
img2 = cv2.imread(image2_path, cv2.IMREAD_UNCHANGED)
if img1 is None:
print(f"错误: 无法读取图片 {image1_path},请检查路径是否正确")
return
if img2 is None:
print(f"错误: 无法读取图片 {image2_path},请检查路径是否正确")
return
# 检查图片尺寸是否相同
if img1.shape != img2.shape:
print("错误: 两张图片尺寸不一致,无法进行按位操作")
print(f"{image1_path} 尺寸: {img1.shape}")
print(f"{image2_path} 尺寸: {img2.shape}")
return
# 检查通道数是否相同
if len(img1.shape) != len(img2.shape) or (len(img1.shape) > 2 and img1.shape[2] != img2.shape[2]):
print("错误: 两张图片通道数不一致")
print(f"{image1_path} 通道数: {img1.shape[2] if len(img1.shape) > 2 else 1}")
print(f"{image2_path} 通道数: {img2.shape[2] if len(img2.shape) > 2 else 1}")
return
# 执行按位异或操作
xor_result = cv2.bitwise_xor(img1, img2)
# 保存结果
cv2.imwrite(output_path, xor_result)
print(f"异或操作完成,结果已保存到: {output_path}")
# 使用示例
if __name__ == "__main__":
# 指定图片路径
image1 = "stream1.webp" # 第一张WebP图片
image2 = "stream2.webp" # 第二张WebP图片
output = "xor_result.webp" # 输出图片路径
# 执行异或操作
webp_xor(image1, image2, output)
|
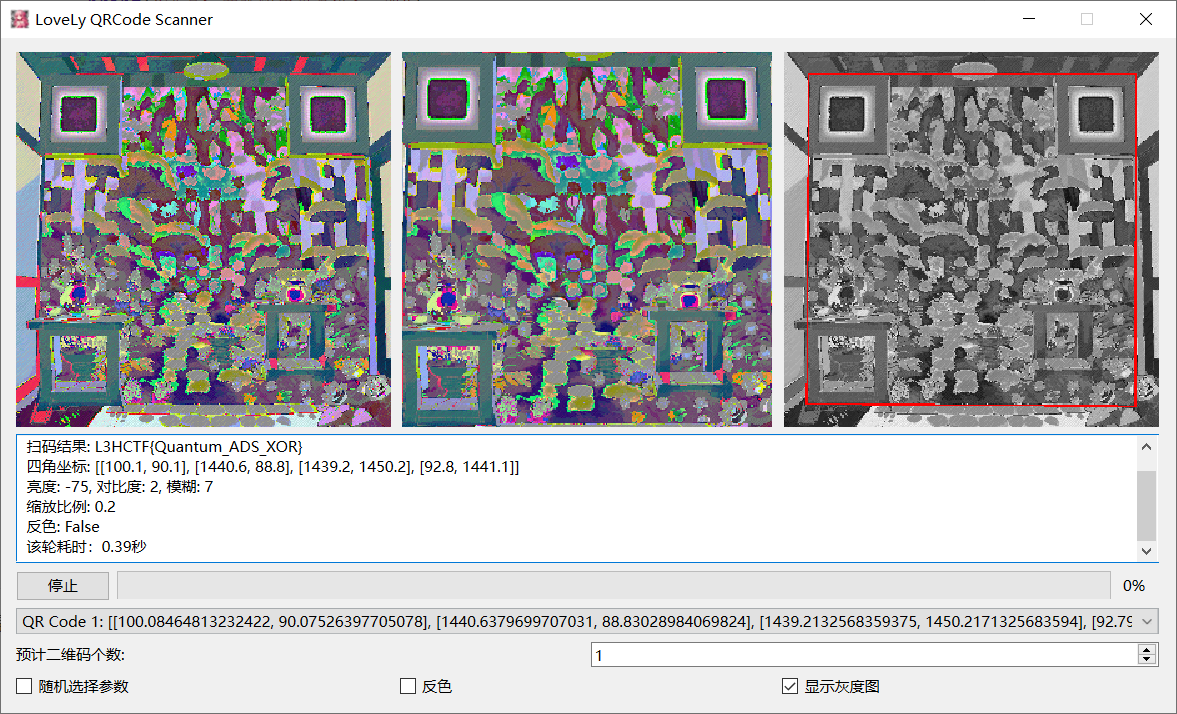
得到新图片,用大佬的工具扫码LoveLy-QRCode-Scanner
Why not read it out?
这个大部分是Miraitowa.师傅做的
大概流程就是先foremost提取图片,然后010查看到原文件尾部有个小端序的base64
aDFudDogSUdOIFJdmlldw==
解密得到IGN,得知大概是游戏,然后题目说了狐狸,谷歌搜索得到tunic游戏语言
https://www.ign.com/articles/tunic-review-xbox-pc-steam
这个链接对照上面得出的图片密文手搓音标对照表
翻译最后五句
1
2
3
4
|
1.the content of flag is:come on little brave fox
2. replace letter o with number 0,letter l with number one
3.replace letter a with symbol @
4.make every letter e uppercase
|
看到这里知道它大概在混淆第一句
直接猜最后一句是空格改成下划线_,当然去翻译也行,最后套上flag格式就行了
